Ensuring that digital systems remain stable, fast, and scalable has become the backbone of software engineering. When applications crash or experience heavy lag, businesses lose both revenue and user trust. Because of this reality, organizations rely heavily on modern operations engineering to keep their platforms running smoothly around the clock. Site Reliability Engineering, or SRE, bridges the gap between software development and traditional IT operations by applying a software engineering mindset to infrastructure problems. If you want to master these concepts from the ground up, exploring specialized resources like Sreschool will help you build a solid foundation in maintaining high-availability systems.
Site Reliability Engineering essentially treats operations as if it were a software problem. Instead of manually configuring servers, fixing repetitive errors, or deploying code by hand, professionals design automated systems that manage themselves. Consequently, this approach minimizes human error, accelerates software deployment cycles, and ensures that digital services can handle millions of concurrent users without breaking. By focusing on automation, architectural resilience, and proactive monitoring, teams can shift their energy away from putting out fires and spend more time building innovative features.
Understanding this balance between rapid feature delivery and platform stability is crucial for any beginner entering the tech industry. Developers naturally want to push new code as fast as possible to satisfy customer demands. Conversely, operations teams traditionally want to limit changes because modifications introduce the risk of system instability. This guide will walk you through the fundamental frameworks, operational core concepts, cultural dynamics, and practical career roadmaps needed to navigate this vital field successfully.
Key Operational Concepts You Must Know
To manage large-scale systems effectively, you must learn to measure performance and availability using precise metrics. Without clear definitions of success, engineering teams cannot determine whether a system is running acceptably or failing. Therefore, the industry relies on a specific set of metrics to align business goals with technical execution.
Service Level Indicators (SLIs)
A Service Level Indicator represents a quantifiable metric that shows how well a specific service is performing in real-time. For example, if you run an e-commerce website, a common SLI would be the latency of the checkout page. You might track the percentage of requests that successfully return a response in less than 200 milliseconds.
Other vital indicators include error rates, system throughput, and data durability. Choosing the right indicators requires you to look closely at the user experience. If a metric does not impact how the user perceives your application, it probably should not serve as an indicator.
Service Level Objectives (SLOs)
Once you define your metrics, you must set specific target values that your team agrees to maintain. This target is your Service Level Objective. For instance, you might state that the system’s availability must hit 99.9% over a rolling 30-day window.
Setting these targets requires careful balance. While achieving 100% availability sounds ideal, it is practically impossible and financially restrictive. Every extra fraction of a decimal point requires massive investments in redundant infrastructure and slows down code deployments significantly.
Service Level Agreements (SLAs)
A Service Level Agreement is a formal, legally binding contract between a service provider and the end customers. It outlines the expected performance levels and details the consequences if the system falls short of those promises. If your application drops below the agreed threshold, your company might have to refund money or face penalties.
Engineers focus heavily on maintaining the internal objectives to guarantee that the external agreement is never breached. As a rule of thumb, your internal target should always be tighter than your customer contract to provide a safe buffer.
+-----------------------------------------------------------+
| Service Level Agreement (SLA) |
| (Legal contract with customers: e.g., 99% uptime) |
| |
| +-------------------------------------------------+ |
| | Service Level Objective (SLO) | |
| | (Internal target with buffer: e.g., 99.9%) | |
| | | |
| | +---------------------------------------+ | |
| | | Service Level Indicator (SLI) | | |
| | | (Real-time metric: e.g., Uptime %) | | |
| | +---------------------------------------+ | |
| +-------------------------------------------------+ |
+-----------------------------------------------------------+
Error Budgets and Risk Management
An error budget represents the total amount of acceptable downtime or failure that your system can tolerate over a specific timeframe. It mathematically equals 100%−SLO. For example, if your objective is 99.9%, your error budget sits at 0.1%.
\text{Error Budget} = 100\% - \text{SLO}
This budget serves as a dynamic control mechanism for development velocity. As long as your system has remaining error budget, developers can aggressively deploy new, high-risk features. However, if a major outage consumes the budget entirely, deployments stop, and the engineering team redirects all focus toward fixing bugs and improving system stability.
Platform Implementation vs. Culture — What’s the Real Difference?
Many organizations mistakenly believe that installing the latest cloud-native tools will automatically fix their operational challenges. True reliability, however, requires a balance between technical platform implementation and an organizational culture that embraces shared responsibility.
Technical Platform Implementation
The engineering side of operations involves building internal developer platforms, deploying automation scripts, and provisioning infrastructure. Engineers write code to orchestrate cloud environments, manage container lifecycles, and direct network traffic safely.
- Infrastructure as Code (IaC): Writing configuration files to automatically deploy, modify, and destroy cloud infrastructure without manual clicking.
- Continuous Integration and Deployment (CI/CD): Building automated pipelines that test code updates and safely deploy them to production servers.
- Observability Networks: Setting up centralized log systems, metric dashboards, and distributed tracing networks to see exactly how data moves through microservices.
- Self-Healing Mechanisms: Configuring automated scripts that automatically reboot failing application instances or scale up server counts when traffic spikes.
Cultural Foundations and Shared Responsibility
In contrast, the cultural element focuses entirely on human behavior, communication styles, and organizational mindsets. A company can possess incredible automation, but if developers and operations teams work in silos, systemic failures will inevitably surface.
- Blameless Postmortems: Examining system failures with the assumption that engineers acted with good intentions based on the information they had. Instead of punishing individuals, teams rewrite processes and improve code to prevent the same mistake.
- Reducing Silos: Forcing developers and infrastructure engineers to share ownership of production health rather than throwing broken code over a wall.
- Eliminating Toil: Fostering a mindset where repetitive, manual tasks are actively despised and prioritized for automation.
- Accepting Failure as Normal: Recognizing that complex distributed systems are inherently prone to breaking, which shifts focus from avoiding all failures to mitigating their impact.
| Operational Aspect | Platform Implementation | Cultural Mindset |
|---|---|---|
| Primary Focus | Automation tools, code, pipelines, cloud configuration | Communication, empathy, alignment, shared ownership |
| Core Goal | Reduce manual efforts through robust infrastructure systems | Eliminate fear of failure and optimize human workflows |
| Typical Artifacts | IaC scripts, dashboards, container registries | Postmortem documents, team manifestos, training sessions |
| Failure Resolution | Automated rollbacks, scaling policies, server reboots | Root-cause analysis, process changes, educational reviews |
Real-World Use Cases of Modern Operations
Looking at theoretical concepts is helpful, but seeing how these methodologies operate in real enterprise environments brings the principles to life. Organizations apply these practices across diverse domains to survive massive scale and unexpected user patterns.
Managing Global Scale Traffic Spikes
Imagine a massive global streaming platform launching the highly anticipated season finale of a popular show. Millions of users click the play button at exactly the same second, causing an unprecedented wave of incoming network traffic.
To survive this surge, operations engineers deploy automated load balancers that spread incoming requests across thousands of servers worldwide. Concurrently, edge caching mechanisms deliver static media content from data centers physically close to the users. This strategy reduces the burden on central databases and keeps playback smooth.
Seamless Zero-Downtime E-Commerce Deployments
A major e-commerce platform needs to release an updated payment gateway on a busy afternoon without disconnecting active shoppers. Rather than scheduling a midnight maintenance window, the team utilizes a progressive delivery strategy.
They implement a canary deployment process, routing a tiny fraction of live user traffic to the new payment system. The monitoring platforms continuously analyze error rates and response times from this isolated group. Since the metrics look stable, the system automatically routes the remaining traffic to the new version, completing the update with zero customer disruption.
+-------------------+
| Global Traffic |
+-------------------+
|
v
+-------------------+
| Load Balancer |
+-------------------+
/ \
(95% Traffic) (5% Traffic)
/ \
v v
+--------------------+ +--------------------+
| Stable Version | | Canary Version |
| (Current App) | | (New Code Test) |
+--------------------+ +--------------------+
Proactive Disaster Recovery for Financial Platforms
A regional banking application experiences a catastrophic hardware failure at its primary data center due to a localized power grid collapse. In a traditional IT environment, this event would trigger hours of downtime while technicians manually restored backups.
Because the team designed their architecture around modern reliability principles, automated health checks immediately flag the entire data center as unresponsive. Instantly, automated routing mechanisms shift live traffic to a fully replicated, active data center in a different region. The end users notice nothing more than a momentary delay on their mobile screens.
Common Mistakes in Operations Engineering
Even well-funded engineering departments frequently fall into traps that undermine their operational efficiency. Identifying these anti-patterns early helps you avoid building fragile systems that exhaust your engineering personnel.
Over-Automating Fragile Processes
Automation is highly beneficial, but writing complex scripts to automate a fundamentally broken, poorly documented workflow causes major issues. When the underlying process changes or breaks unexpectedly, your automation script will simply amplify the errors at lightning speed.
Before writing a single line of automation code, you must manually clean up, simplify, and stabilize the target workflow. If a process cannot run reliably by hand, converting it into code will only hide architectural flaws until they explode in production.
Toxic On-Call Schedules and Alert Fatigue
Many organizations configure their alerting systems to trigger high-priority text messages for every minor anomaly, such as a temporary CPU spike on a non-critical server. Consequently, engineers receive notifications at all hours of the night for events that do not actually require immediate human intervention.
\text{Alert Frequency} \propto \frac{1}{\text{Threshold Precision}}
This dynamic leads straight to alert fatigue, where exhausted engineers begin ignoring critical notifications because they assume they are false alarms. Alerts should only fire when a user-facing objective is genuinely in jeopardy, and every notification must come with a clear, actionable instruction.
+-----------------------------------------------------------+
| Alert Evaluation Circle |
+-----------------------------------------------------------+
| |
| Is this issue currently violating an active SLO? |
| / \ |
| (Yes) (No) |
| / \ |
| v v |
| Trigger Immediate On-Call Alert. Silence alert. |
| Human intervention required now. Log as ticket. |
| |
+-----------------------------------------------------------+
Treating Observability as a Dashboard Construction Project
Building hundreds of vibrant, complex charts on office walls creates a false sense of security. If your engineering team has to stare at a screen constantly to discover that something is broken, your monitoring framework has failed.
True observability means your system actively collects meaningful data points that allow you to quickly trace the root cause of an unpredicted system state. Focus on building clean, automated alerts that notify you of deviations, rather than assembling confusing walls of graphs that no one can interpret during an emergency.
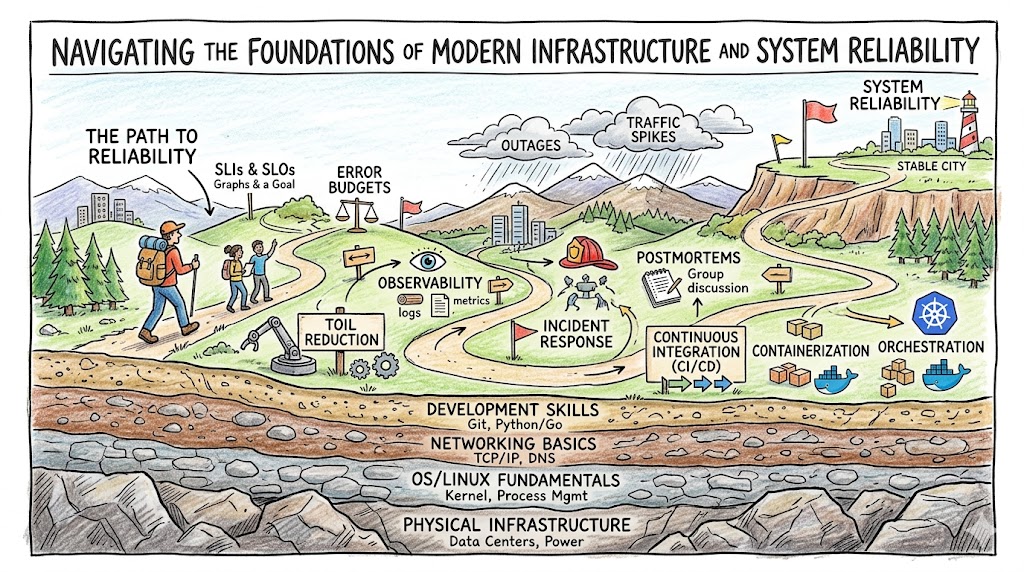
How to Become an Operations Expert — Career Roadmap
Transitioning into the world of reliability and operations engineering requires a structured learning path. Because this role touches both development and infrastructure, you need to cultivate a broad, versatile technical skillset.
Step 1: Master the Core Operating System Fundamentals
Before exploring advanced cloud platforms, you must understand the environment where your code actually executes. Spend time learning how operating systems handle basic processes, allocate hardware memory, and manage storage systems.
- Linux Internals: Learn how to comfortably navigate the command-line interface, manage system permissions, and inspect running processes.
- Networking Basics: Understand how TCP/IP protocols work, how DNS routes web requests across the globe, and how firewalls protect private servers.
- Resource Analysis: Practice using native system utilities to track memory leaks, CPU saturation, and storage bottlenecks.
Step 2: Develop Strong Coding and Automation Skills
An operations expert who cannot write code will eventually become a bottleneck for the organization. You do not need to build complex front-end websites, but you must write clean, maintainable scripts to automate platform operations.
- Python or Go: Master at least one modern language widely used for building cloud infrastructure tooling and automated workflows.
- Shell Scripting: Learn to write Bash scripts to chain system utilities together and perform rapid, ad-hoc server maintenance tasks.
- Version Control: Commit all your scripts to Git registries to track changes, collaborate safely with team members, and roll back broken updates.
Step 3: Embrace Containerization and Cloud Architecture
Modern applications no longer run directly on bare metal servers. Instead, companies wrap their software inside isolated software packages called containers to guarantee consistent behavior across different hardware environments.
- Docker: Learn how to package applications, write optimized container blueprints, and manage isolated virtual network bridges.
- Kubernetes: Study how this orchestration engine coordinates thousands of containers across clusters of physical machines, manages load distribution, and handles self-healing.
- Cloud Platforms: Experiment with major cloud providers to understand how to provision virtual servers, managed databases, and cloud networks.
+-------------------------------------------------------------+
| Cloud Infrastructure Hierarchy |
+-------------------------------------------------------------+
| |
| +-----------------------------------------------------+ |
| | Orchestration Layer (Kubernetes) | |
| | (Manages, scales, and heals containers globally) | |
| +-----------------------------------------------------+ |
| | |
| +-----------------------------------------------------+ |
| | Container Layer (Docker) | |
| | (Packages application code and dependencies) | |
| +-----------------------------------------------------+ |
| | |
| +-----------------------------------------------------+ |
| | Infrastructure Layer (Cloud/OS) | |
| | (Virtual networks, Linux kernels, raw compute) | |
| +-----------------------------------------------------+ |
| |
+-------------------------------------------------------------+
Step 4: Implement Comprehensive Observability Strategies
You cannot fix a system flaw if you cannot see what is happening inside it. Therefore, mastering the collection and analysis of telemetry data is a non-negotiable step on your engineering roadmap.
- Metrics Gathering: Use collection tools to gather operational data points like memory consumption, active request rates, and response errors.
- Log Management: Configure central indexing storage networks to pull raw application printouts together so you can easily search for stack traces.
- Distributed Tracing: Learn to follow individual user requests as they hop across dozens of isolated microservices to pinpoint exactly which asset causes a delay.
FAQ Section
- What is the primary difference between DevOps and Site Reliability Engineering?
DevOps represents a broad organizational philosophy focused on breaking down traditional barriers between software development and IT support teams. Site Reliability Engineering acts as a specific, highly concrete implementation of that philosophy by utilizing prescriptive software engineering practices to solve operational problems.
- Can a beginner jump directly into an engineering role focused on reliability?
Yes, beginners can absolutely enter this specialty provided they possess solid foundations in fundamental Linux operations, general programming logic, and basic web networking. Many companies now offer junior infrastructure positions and structured apprenticeships designed specifically to train promising candidates on real enterprise systems.
- How do engineering teams balance system reliability with rapid product delivery?
Organizations balance these competing goals mathematically by enforcing strict error budgets based on calculated Service Level Objectives. If the application retains plenty of remaining budget, developers can release new features rapidly; if the budget drains entirely, feature deployments halt until stability restores.
- Which programming language should I learn first for infrastructure automation?
Python remains an excellent first choice due to its highly readable syntax, massive ecosystem of third-party automation tools, and extensive enterprise adoption. Alternatively, Go has become incredibly popular for building modern cloud utilities, making it another highly lucrative language to study.
- Why is a blameless culture considered critical for maintaining stable platforms?
If an organization punishes employees whenever systems break, engineers will naturally hide mistakes, delay reporting issues, and avoid working on high-risk, innovative components. A blameless approach encourages transparent communication, which allows teams to identify the systemic vulnerabilities behind human errors.
- What exactly is toil in the context of system operations?
Toil refers to manual, repetitive, operational tasks that lack long-term strategic value and scale linearly with the growth of the system infrastructure. Examples include manually resetting user passwords or running routine cleanup scripts every morning, both of which engineers should target for automation.
- How often should a company update its internal Service Level Objectives?
Teams should formally re-evaluate their performance objectives at regular intervals or whenever the application undergoes a major architectural overhaul. If your users consistently complain while your internal charts show perfect health, your objectives do not accurately reflect the actual user experience.
- Is deep knowledge of cloud providers mandatory to become an operations expert?
While understanding cloud architecture is highly valuable, mastering fundamental operating system mechanics, general networking, and automation logic is far more critical. Cloud platforms update their interfaces constantly, but core concepts like memory management, routing protocols, and disk storage remain uniform.
Final Summary
Embracing the principles of modern system operations transforms how organizations build, deploy, and scale application software. Rather than treating infrastructure management as a series of unpredictable manual fires, engineering teams can use software principles to build highly resilient, autonomous platforms. By establishing precise performance indicators, cultivating a blameless culture of shared ownership, and continually automating repetitive task workflows, you can protect your systems from inevitable hardware failures and traffic surges. Ultimately, mastering this discipline is not about avoiding production failures entirely, but rather about building robust architectures that absorb unexpected issues gracefully while delivering an exceptional experience to your users.