Introduction
Engineers often face support gaps right after delivery: a CI/CD pipeline fails on release day, a cloud cost spike appears overnight, or a Kubernetes rollout stalls while customers wait. Therefore, teams lose time while they search logs, chase owners, and retry changes without a clear plan. Why this matters: every delay increases downtime risk and delivery pressure.
Support Services matters today because modern DevOps stacks change quickly and run across many platforms, so teams need reliable help that keeps systems stable after implementation. Moreover, 24/7 monitoring and proactive troubleshooting reduce surprises and keep delivery moving when business demand stays high. Why this matters: continuous support protects reliability and customer trust.
In this guide, you will learn what Support Services means in a DevOps context, how it works step by step, and how to apply it safely with real scenarios and best practices. As a result, you will gain a practical support playbook that improves uptime, performance, and operational confidence. Why this matters: you should finish with clear actions, not generic advice.
What Is Support Services?
Support Services means ongoing, expert assistance that keeps your DevOps and cloud environment healthy after teams implement pipelines, platforms, and automation. Instead of treating support as a basic helpdesk, Support Services focuses on operational outcomes such as uptime, incident response, performance tuning, and continuous improvement. Why this matters: real support protects production, not only tickets.
In day-to-day DevOps work, Support Services helps developers and DevOps engineers handle build failures, deployment issues, misconfigurations, and scaling challenges across tools and environments. Additionally, it covers post-implementation support, performance optimization, and ongoing maintenance so systems evolve with business growth. Why this matters: most failures happen after go-live, so steady support prevents backsliding.
Support Services stays practical because it connects monitoring signals to root-cause diagnosis and connects fixes to validation and documentation. Consequently, teams reduce downtime, reduce operational risk, and improve efficiency across their technology stack. Why this matters: a stable stack helps teams ship features faster with fewer fire drills.
Why Support Services Is Important in Modern DevOps & Software Delivery
Modern software delivery relies on rapid releases, shared ownership, and always-on platforms, so small issues can quickly ripple across pipelines and production. Therefore, teams need support that responds fast and also improves systems over time. Why this matters: speed without stability causes repeated incidents.
Organizations widely adopt CI/CD, cloud infrastructure, and automation, yet those environments still demand constant tuning, patching, and incident readiness. Moreover, DevOps work spans pipelines, cloud management, and platform reliability, so Support Services helps teams keep operations smooth and optimized. Why this matters: tool complexity increases, so reliable help reduces operational drag.
Support Services also solves business problems that engineering alone cannot absorb, such as 24/7 coverage needs, performance bottlenecks, and urgent technical issues that appear outside normal work hours. In addition, proactive monitoring and troubleshooting reduce outages and protect delivery timelines. Why this matters: consistent operations directly support revenue and customer experience.
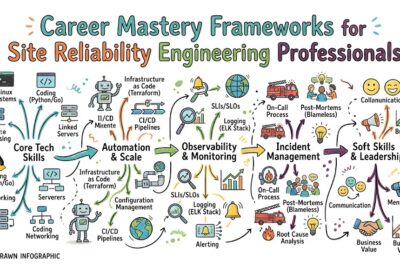
Core Concepts & Key Components
24/7 Monitoring and Signal Awareness
Purpose: Keep continuous visibility into systems so teams catch issues early.
How it works: Support teams watch health signals such as service availability, latency, error rates, infrastructure capacity, and critical alerts, then they act on early warning signs.
Where it is used: Production applications, CI/CD runners, Kubernetes clusters, cloud services, and critical data pipelines. Why this matters: early detection prevents small issues from turning into outages.
Proactive Troubleshooting and Prevention
Purpose: Reduce repeated incidents by fixing underlying causes.
How it works: Teams review incident patterns, recent changes, and recurring alerts, then they adjust configurations, add guardrails, and improve runbooks.
Where it is used: Flaky pipelines, unstable deployments, capacity hot spots, and noisy monitoring setups. Why this matters: prevention saves more time than repeated firefighting.
Real-Time Issue Resolution and Incident Handling
Purpose: Restore service quickly when failures affect delivery or customers.
How it works: Support engineers triage alerts, isolate the failure domain, apply a safe fix, and validate recovery through targeted checks and monitoring.
Where it is used: Release-day failures, production incidents, infrastructure outages, and security-related pipeline blocks. Why this matters: fast recovery reduces impact and restores trust.
Post-Implementation Support and Ongoing Maintenance
Purpose: Keep systems stable after teams complete initial setup or migration.
How it works: Support teams help with upgrades, patching, dependency alignment, and operational hygiene tasks that teams often postpone.
Where it is used: Cloud environment maintenance, Kubernetes upgrades, CI tool upgrades, and observability platform maintenance. Why this matters: neglected maintenance increases risk and cost over time.
Performance Optimization and Continuous Improvement
Purpose: Improve efficiency, reliability, and cost control without slowing delivery.
How it works: Teams analyze bottlenecks, tune resource limits, refine caching and scaling rules, and optimize pipeline stages and build times.
Where it is used: Slow builds, high latency services, expensive cloud usage, and capacity planning. Why this matters: optimization improves customer experience and reduces waste.
Customized Support Plans and Coverage Alignment
Purpose: Match support to business needs and technical reality.
How it works: Support teams shape coverage around critical systems, peak delivery windows, and tool stacks across DevOps pipelines and cloud management.
Where it is used: Enterprises with strict SLAs, startups with lean teams, and platforms with global users. Why this matters: the right plan prevents gaps and improves accountability.
Why this matters: these core components create reliable operations while teams keep building and releasing at speed.
How Support Services Works (Step-by-Step Workflow)
Step 1: Teams define what “healthy operations” means for their stack, including uptime targets, release frequency, and critical services. Therefore, support starts with clear outcomes, not vague expectations. Why this matters: clear outcomes reduce confusion during incidents.
Step 2: Support teams set up monitoring coverage and alert priorities, so signals reflect real customer impact and real risk. Next, teams confirm escalation rules and ownership boundaries, so response stays fast and consistent. Why this matters: good signals and clear ownership shorten response time.
Step 3: When an issue appears, the support team triages quickly, checks recent changes, and narrows the failure domain. Then, they apply a safe fix and validate recovery using targeted tests and live metrics. Why this matters: validation prevents repeat failures and hidden regressions.
Step 4: After recovery, teams document what happened, what fixed it, and what prevention action will stop recurrence. Finally, support teams perform performance optimization and maintenance work so systems keep evolving with business growth. Why this matters: learning and prevention protect future releases.
Real-World Use Cases & Scenarios
A DevOps engineer may face a recurring pipeline failure after a tool update, so Support Services helps isolate version conflicts, stabilize runners, and reduce build flakiness. Moreover, the team can tighten validation steps so releases stop failing late in the process. Why this matters: stable pipelines protect delivery speed and team morale.
A cloud engineer may notice rising infrastructure costs and intermittent latency, so Support Services helps tune autoscaling, adjust resource limits, and optimize performance while protecting availability. Additionally, proactive monitoring catches capacity issues before they impact users. Why this matters: performance and cost control both affect business outcomes.
An SRE may handle alert storms during peak traffic, so Support Services helps reduce noise, improve alert routing, and focus on signals that reflect real risk. Consequently, on-call workload drops while reliability improves. Why this matters: calmer on-call improves response quality and retention.
A QA team may struggle with unstable test environments, so Support Services helps stabilize environments, align configuration across stages, and improve CI feedback loops. Therefore, developers get faster, more reliable feedback and ship higher-quality releases. Why this matters: consistent environments reduce defects and rework.
Benefits of Using Support Services
- Productivity: Teams resolve issues faster, so engineers spend more time building and less time guessing.
- Reliability: Teams reduce downtime through monitoring, proactive troubleshooting, and real-time issue resolution.
- Scalability: Teams scale operations with repeatable processes, maintenance routines, and performance optimization practices.
- Collaboration: Developers, DevOps, QA, Cloud, and SRE teams align around shared signals, shared runbooks, and shared outcomes.
Why this matters: these benefits protect delivery velocity while improving production stability.
Challenges, Risks & Common Mistakes
Teams often share incomplete context, so troubleshooting takes longer than it should. Therefore, teams should capture versions, recent changes, logs, and clear reproduction steps before escalation. Why this matters: complete context speeds up resolution and reduces back-and-forth.
Teams sometimes chase quick fixes and skip validation, so issues return during the next release or traffic spike. Instead, teams should validate changes with smoke tests, rollback plans, and monitoring checks that confirm recovery. Why this matters: validation protects users and prevents repeated incidents.
Teams can also expose security risk when they share secrets in messages or grant broad access for convenience. Consequently, teams should redact credentials, rotate tokens, and follow least-privilege access during every support interaction. Why this matters: security mistakes can cost more than the original outage.
Comparison Table
| Point | Traditional Support Style | Support Services Style for DevOps Delivery |
|---|---|---|
| 1 | React after failures | Detect early with 24/7 monitoring |
| 2 | Fix symptoms only | Diagnose root cause and prevent recurrence |
| 3 | Unstructured triage | Follow a clear incident workflow |
| 4 | Manual checks | Use repeatable validation and runbooks |
| 5 | No performance focus | Optimize performance continuously |
| 6 | Maintenance gets delayed | Run ongoing maintenance regularly |
| 7 | Tool silos | Connect pipeline, cloud, and operations |
| 8 | Slow escalations | Use clear escalation and ownership rules |
| 9 | No learning loop | Document fixes and improve processes |
| 10 | One-size plan | Use customized support plans |
| 11 | Limited collaboration | Align Dev, QA, DevOps, Cloud, and SRE |
| 12 | Higher downtime risk | Reduce risk through proactive troubleshooting |
Why this matters: the modern approach improves reliability, speed, and teamwork without adding chaos.
Best Practices & Expert Recommendations
First, define measurable outcomes such as uptime targets, pipeline success rate, and incident response goals, because metrics keep support focused. Moreover, teams should align alert priorities with customer impact, so responders act on the right signals first. Why this matters: clear goals and clear signals reduce confusion during critical moments.
Next, standardize triage with a simple checklist: recent changes, scope, blast radius, and rollback options. Then, validate every fix with monitoring checks and targeted tests, so teams confirm recovery before closing the loop. Why this matters: structure and validation prevent repeat incidents.
Also, invest in prevention: tune alerts, improve dashboards, update runbooks, and schedule maintenance and performance optimization work. Consequently, teams reduce future escalations and protect delivery timelines. Why this matters: prevention converts support into long-term stability.
Who Should Learn or Use Support Services?
Developers should use Support Services when build failures, deployment blocks, or environment drift slows feature delivery. Therefore, they can resolve issues faster and learn repeatable troubleshooting habits. Why this matters: developers ship faster with stable delivery systems.
DevOps engineers should use Support Services because they own pipelines, automation, and platform operations across multiple tools and environments. Moreover, they often support releases under tight deadlines, so reliable help reduces delivery risk. Why this matters: DevOps work needs consistent operational coverage.
Cloud engineers, QA engineers, and SREs should also use Support Services because they manage reliability signals, environments, and performance requirements across stages and production. Additionally, beginners gain confidence through guided workflows, while experienced engineers accelerate resolution for complex edge cases. Why this matters: the same support model helps every experience level.
FAQs – People Also Ask
1) What is Support Services in a DevOps environment?
Support Services provides ongoing help for monitoring, troubleshooting, maintenance, and performance improvements after implementation.
It keeps pipelines and platforms stable while teams keep shipping. Why this matters: stable operations protect delivery speed.
2) Why do teams need 24/7 monitoring with Support Services?
24/7 monitoring helps teams detect issues early and respond before customers feel impact.
It also reduces surprise outages outside work hours. Why this matters: early detection reduces downtime.
3) How does Support Services help CI/CD pipelines?
Support Services helps diagnose failures, stabilize runners, and improve validation steps in the pipeline.
It also reduces repeated build and release failures over time. Why this matters: pipeline health controls release velocity.
4) Does Support Services include performance optimization?
Yes, Support Services includes performance optimization and ongoing maintenance as part of long-term stability.
Teams can tune scaling, resource limits, and bottlenecks safely. Why this matters: performance affects users and cost.
5) How does Support Services support cloud infrastructure?
Support Services helps manage cloud environments, reduce operational risk, and keep systems scalable and reliable.
It also supports post-implementation needs as environments evolve. Why this matters: cloud changes require continuous care.
6) Is Support Services useful for SRE and incident response?
Yes, it supports real-time issue resolution and structured incident handling.
It also improves prevention through better runbooks and monitoring tuning. Why this matters: faster recovery protects customers.
7) Can beginners use Support Services effectively?
Yes, beginners can follow guided steps and learn the “why” behind fixes through real problems.
They can also build confidence with repeatable workflows. Why this matters: real scenarios teach faster than theory alone.
8) What common mistake slows support outcomes the most?
Teams often share incomplete context, so responders waste time collecting basics.
Teams should share versions, logs, recent changes, and expected behavior upfront. Why this matters: good inputs speed resolution.
9) How can teams reduce risk during urgent fixes?
Teams should keep a rollback plan, validate changes, and confirm recovery with monitoring checks.
They should also document the fix and prevention steps immediately. Why this matters: safe fixes prevent repeat outages.
10) How do teams measure the value of Support Services?
Teams can track MTTR, incident recurrence, pipeline success rate, and downtime reduction.
They can also track performance and cost improvements after optimization work. Why this matters: measurable outcomes prove operational value.
Branding & Authority
If you want dependable Support Services for real DevOps operations, you should rely on a platform that connects monitoring, troubleshooting, and continuous improvement into one practical support model. Therefore, DevOpsSchool provides Support Services that focus on smooth, efficient operations for DevOps and cloud infrastructure, including 24/7 monitoring, proactive troubleshooting, real-time issue resolution, post-implementation support, performance optimization, and ongoing maintenance. Moreover, the page also highlights broad support coverage across domains such as DevOps, DevSecOps, SRE, MLOps, AIOps, DataOps, NoOps, FinOps, Kubernetes, AWS, Azure, and GitOps. Why this matters: broad coverage with clear outcomes reduces downtime and supports continuous delivery.
Strong mentorship helps support stay practical because tools change quickly while operational thinking must stay consistent. Consequently, Rajesh Kumar brings 20+ years of hands-on expertise that spans DevOps & DevSecOps, Site Reliability Engineering (SRE), DataOps, AIOps & MLOps, Kubernetes & Cloud Platforms, and CI/CD & Automation. Therefore, teams can align urgent fixes with scalable practices, safer automation, and stronger reliability habits instead of repeating the same incidents. Why this matters: experienced guidance improves both short-term recovery and long-term resilience.
Call to Action & Contact Information
Email: contact@DevOpsSchool.com
Phone & WhatsApp (India): +91 7004 215 841
Phone & WhatsApp (USA): 1800 889 7977