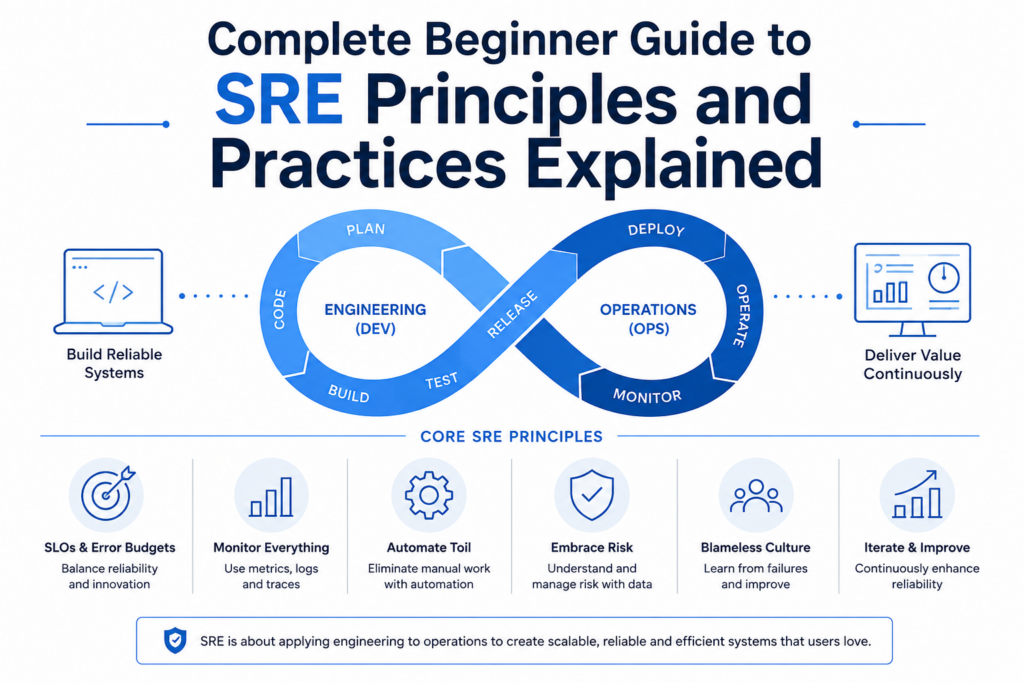
System Reliability Engineering, commonly known as SRE, is a discipline that combines software engineering with IT operations to build highly reliable, scalable, and efficient systems. Modern organizations depend heavily on digital services, and even a few minutes of downtime can impact customer trust, revenue, and business reputation. Because of this, companies need professionals who can ensure systems remain available while supporting rapid innovation and continuous delivery.
For beginners, SRE may seem like a complex field filled with automation tools, monitoring platforms, incident management processes, and infrastructure concepts. However, the core goal remains simple: create reliable services that meet business expectations while allowing development teams to move quickly. Organizations worldwide are adopting SRE practices because they help balance stability and innovation.
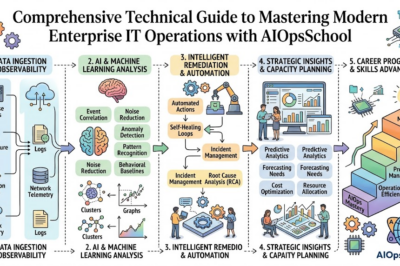
Many professionals begin their SRE journey through structured learning platforms such as Sreschool, where they can understand reliability engineering principles, monitoring strategies, automation frameworks, and production operations. This guide explores the essential concepts, operational practices, real-world applications, career pathways, and common challenges that every beginner should understand before entering the world of Site Reliability Engineering.
Understanding the Foundation of Site Reliability Engineering
Site Reliability Engineering originated from the idea that operational problems can be solved through engineering practices rather than manual administration. Traditional operations teams often spend significant time responding to incidents, performing repetitive tasks, and maintaining infrastructure manually. SRE transforms this approach by treating operational challenges as software problems that can be automated, measured, and improved continuously.
The primary objective of SRE is to create reliable services without slowing down innovation. Instead of focusing solely on uptime, SRE teams establish measurable reliability targets and use data-driven decision-making. They create monitoring systems, automate repetitive workflows, improve deployment pipelines, and build mechanisms that reduce operational risk.
As organizations scale, infrastructure becomes increasingly complex. Multiple applications, cloud environments, databases, APIs, and distributed systems create operational challenges that cannot be managed manually. SRE practices provide a structured framework for managing complexity while maintaining service quality. This balance between engineering excellence and operational reliability forms the foundation of modern SRE practices.
Why SRE Matters in Modern Technology Environments
Businesses today operate in highly competitive digital markets where customers expect services to be available around the clock. Users have little tolerance for slow applications, failed transactions, or prolonged outages. Consequently, organizations must maintain high reliability standards while releasing new features rapidly.
SRE helps achieve this balance through measurable objectives and automation-driven operations. Rather than relying on subjective opinions about system health, SRE teams use metrics and service-level targets to guide decisions. This approach allows organizations to understand acceptable risk levels and allocate resources effectively.
Furthermore, modern infrastructures often span multiple cloud providers, microservices architectures, container platforms, and globally distributed systems. Managing such environments manually becomes unsustainable. SRE introduces automation, observability, incident response frameworks, and reliability-focused engineering practices that enable organizations to operate at scale while minimizing operational overhead.
As a result, companies adopting SRE often experience improved uptime, faster recovery times, better customer experiences, and increased engineering productivity.
Key Operational Concepts You Must Know
Service Level Indicators (SLIs)
Service Level Indicators represent measurable metrics that reflect service performance from the user’s perspective. Examples include request success rates, response times, availability percentages, and latency measurements. These indicators help teams understand how systems perform under real-world conditions.
SLIs serve as the foundation for reliability measurement because they provide objective data about service quality. Rather than assuming a system is healthy, engineers analyze metrics to determine whether performance meets expectations. This data-driven approach allows organizations to identify issues early and prioritize improvements effectively.
When implemented correctly, SLIs create transparency across engineering teams. Everyone shares a common understanding of service health, which reduces confusion and improves operational decision-making. Consequently, SLIs play a critical role in modern reliability engineering practices.
Service Level Objectives (SLOs)
Service Level Objectives define reliability targets based on Service Level Indicators. For example, a service may require 99.9% availability or a response time below a specified threshold. These objectives establish clear expectations for system performance.
SLOs help organizations balance innovation and reliability. If reliability exceeds targets significantly, teams can focus on feature development. Conversely, if reliability falls below targets, engineering efforts shift toward improving stability and reducing operational risk.
This framework prevents organizations from pursuing unrealistic perfection while maintaining customer satisfaction. Therefore, SLOs are among the most important concepts every SRE professional must understand.
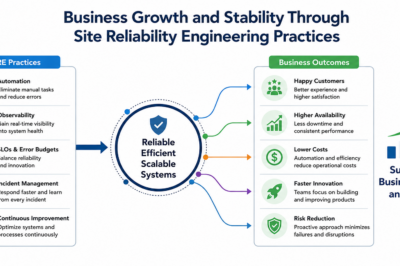
Error Budgets
Error budgets represent the acceptable amount of unreliability allowed within a service. They are directly linked to SLOs and help teams make informed decisions about deployments, feature releases, and operational improvements.
For example, if a service has a 99.9% availability target, a small amount of downtime becomes acceptable. This allowance creates flexibility for experimentation and innovation while maintaining reliability standards.
Error budgets encourage collaboration between development and operations teams because both groups share responsibility for managing reliability. This shared accountability helps reduce conflicts and aligns engineering priorities with business goals.
Observability
Observability refers to the ability to understand system behavior through metrics, logs, and traces. Modern systems generate vast amounts of operational data, and observability tools help engineers analyze this information effectively.
Metrics provide quantitative measurements, logs capture detailed events, and traces show request flows across distributed systems. Together, these components enable teams to diagnose issues quickly and understand system performance comprehensively.
Strong observability practices reduce troubleshooting time, improve incident response effectiveness, and support proactive reliability management. As infrastructures become increasingly distributed, observability becomes a fundamental operational requirement.
Automation
Automation lies at the heart of SRE. Repetitive tasks consume valuable engineering resources and often introduce human errors. By automating operational processes, teams improve consistency, efficiency, and reliability.
Common automation examples include infrastructure provisioning, deployment pipelines, monitoring configurations, backup management, scaling operations, and incident response workflows. These automated processes reduce manual effort and allow engineers to focus on higher-value activities.
Organizations that invest heavily in automation typically experience improved operational efficiency, reduced downtime, and faster service delivery.
Core Principles That Drive Successful SRE Teams
Successful SRE organizations follow several guiding principles that shape operational practices and engineering decisions. One principle emphasizes eliminating manual toil wherever possible. Toil refers to repetitive, predictable work that does not create long-term value. Reducing toil enables engineers to focus on innovation and reliability improvements.
Another principle involves measuring everything. Reliability decisions should be based on data rather than assumptions. Metrics, dashboards, alerts, and reports provide the visibility required to manage complex systems effectively.
Continuous improvement also plays a critical role. Every incident, outage, or operational challenge presents an opportunity to learn and strengthen systems. SRE teams conduct post-incident reviews, identify root causes, and implement corrective actions to prevent recurrence.
Finally, collaboration remains essential. Reliability is not solely the responsibility of operations teams. Developers, architects, product managers, and SRE professionals must work together to achieve shared goals.
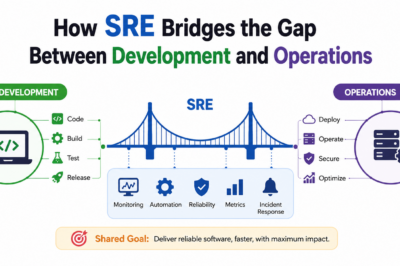
Platform Implementation vs. Culture — What’s the Real Difference?
Many organizations mistakenly believe that purchasing monitoring tools, cloud platforms, or automation software automatically creates an SRE practice. While technology platforms provide important capabilities, they represent only one part of the equation.
Platform implementation focuses on technical solutions. This includes monitoring systems, observability platforms, automation frameworks, deployment pipelines, infrastructure tools, and incident management systems. These technologies enable teams to execute reliability practices efficiently.
Culture, however, determines how people use these tools. A strong SRE culture promotes shared ownership, continuous learning, accountability, transparency, and collaboration. Teams embrace reliability as a collective responsibility rather than assigning blame when incidents occur.
Organizations with advanced platforms but weak culture often struggle to achieve reliability goals. Conversely, teams with strong cultural foundations can achieve significant success even with limited tooling. The most effective SRE environments combine robust technical platforms with a culture that prioritizes learning, improvement, and operational excellence.
Ultimately, technology enables reliability, but culture sustains it.
Incident Management and Operational Excellence
Incidents are inevitable in complex systems. Hardware failures, software bugs, configuration errors, network issues, and external dependencies can all cause disruptions. Therefore, effective incident management forms a critical component of SRE practices.
Incident management begins with detection. Monitoring systems identify anomalies and trigger alerts when predefined thresholds are exceeded. Rapid detection minimizes customer impact and accelerates response efforts.
Next comes coordination. Teams establish clear communication channels, assign responsibilities, and follow structured response procedures. Effective coordination prevents confusion during high-pressure situations.
After resolution, teams conduct post-incident reviews. These reviews focus on understanding what happened, identifying contributing factors, and implementing preventive measures. The objective is learning and improvement rather than assigning blame.
This systematic approach enables organizations to improve resilience continuously and reduce the likelihood of recurring issues.
Capacity Planning and Scalability
As businesses grow, system demand increases. Applications must handle higher traffic volumes, larger datasets, and more complex workloads. Capacity planning ensures infrastructure resources remain sufficient to meet future demands.
SRE teams analyze historical usage patterns, forecast growth trends, and identify potential bottlenecks. They use this information to make informed scaling decisions before performance issues affect users.
Scalability strategies often include load balancing, horizontal scaling, auto-scaling mechanisms, caching systems, and distributed architectures. These techniques enable services to handle increasing workloads efficiently.
Proper capacity planning prevents resource shortages, reduces operational risk, and supports long-term business growth. Consequently, scalability remains a key responsibility within modern SRE environments.
Real-World Use Cases of Modern Operations
E-Commerce Platforms
Online retail platforms experience significant traffic fluctuations during promotions, seasonal events, and product launches. SRE practices help these businesses maintain availability and performance under varying workloads.
Engineers implement auto-scaling systems, monitor transaction success rates, and establish reliability objectives for critical customer journeys. These measures ensure users can browse products, complete purchases, and access services without interruption.
Additionally, incident response frameworks enable rapid recovery from outages, minimizing revenue loss and customer dissatisfaction.
Financial Services
Financial systems require exceptional reliability because downtime can directly affect customer assets and transactions. SRE teams establish strict monitoring, redundancy, and recovery mechanisms to support mission-critical operations.
They track transaction latency, payment success rates, database performance, and service availability continuously. Automated failover systems and disaster recovery strategies further strengthen resilience.
These practices help financial institutions maintain trust while meeting demanding regulatory and operational requirements.
Cloud Service Providers
Cloud platforms operate large-scale infrastructures supporting millions of users and applications. Reliability engineering plays a central role in maintaining service quality across distributed environments.
SRE teams automate infrastructure management, optimize resource allocation, monitor system health, and coordinate large-scale incident responses. They also conduct capacity planning to accommodate growing customer demands.
Without these practices, maintaining reliability at cloud scale would be nearly impossible.
Streaming and Media Services
Streaming platforms depend on consistent performance and low latency to deliver high-quality user experiences. SRE teams monitor content delivery networks, streaming performance metrics, and backend services continuously.
They optimize infrastructure, automate scaling operations, and implement redundancy mechanisms to ensure uninterrupted service delivery. These efforts help platforms support millions of simultaneous users during peak demand periods.
Common Mistakes in Operations Engineering
Ignoring Reliability Metrics
Many organizations focus heavily on feature development while neglecting reliability measurements. Without meaningful metrics, teams struggle to understand service health and identify improvement opportunities.
Reliable operations require clear visibility into performance, availability, latency, and error rates. Ignoring these indicators often results in unexpected outages and customer dissatisfaction.
Therefore, organizations should establish measurable objectives and monitor them consistently.
Overreliance on Manual Processes
Manual operations increase the likelihood of human errors and create scalability challenges. As infrastructure complexity grows, manual approaches become increasingly unsustainable.
Automation improves consistency, accelerates execution, and reduces operational risk. Teams that delay automation often spend excessive time performing repetitive tasks instead of improving systems strategically.
Consequently, automation should remain a priority throughout the operational lifecycle.
Poor Incident Documentation
Incidents provide valuable learning opportunities. However, many teams fail to document events adequately or conduct thorough reviews.
Without documentation, organizations lose critical insights and may repeat the same mistakes. Effective post-incident analysis enables continuous improvement and strengthens long-term reliability.
Documentation also supports knowledge sharing across teams and improves future response efforts.
Alert Fatigue
Excessive alerts overwhelm engineers and reduce response effectiveness. When monitoring systems generate large volumes of low-value notifications, important issues may be overlooked.
SRE teams must design alerting strategies carefully. Alerts should indicate actionable problems requiring immediate attention. This approach improves operational efficiency and reduces engineer burnout.
How to Become an Operations Expert — Career Roadmap
Building expertise in operations engineering requires a combination of technical knowledge, practical experience, and continuous learning. Beginners should start by understanding operating systems, networking fundamentals, cloud computing concepts, and Linux administration.
Once foundational skills are established, learning automation tools becomes important. Infrastructure automation, configuration management, scripting, and deployment pipelines provide valuable operational capabilities. These skills help engineers manage environments efficiently and reduce manual effort.
Monitoring and observability knowledge should follow. Understanding metrics, logs, traces, dashboards, and alerting systems enables professionals to diagnose issues and maintain service health effectively.
As experience grows, engineers can expand into advanced areas such as distributed systems, cloud architecture, performance optimization, capacity planning, and reliability engineering frameworks. Practical experience remains essential because real-world operational challenges provide valuable learning opportunities.
Recommended Learning Path
- Linux administration fundamentals
- Networking and system architecture
- Cloud computing platforms
- Scripting and programming
- Infrastructure automation
- Monitoring and observability
- Containerization technologies
- CI/CD implementation
- Incident management practices
- Reliability engineering methodologies
Skills Employers Commonly Seek
| Technical Skills | Operational Skills |
|---|---|
| Linux Administration | Incident Response |
| Python or Go | Root Cause Analysis |
| Cloud Platforms | Communication |
| Monitoring Tools | Collaboration |
| Automation Frameworks | Documentation |
| Kubernetes | Reliability Planning |
| CI/CD Pipelines | Problem Solving |
| Infrastructure as Code | Continuous Improvement |
Developing both technical and operational competencies creates a strong foundation for long-term success in reliability engineering careers.
Future Trends Shaping Site Reliability Engineering
SRE continues evolving as technology landscapes change. Artificial intelligence and machine learning increasingly support monitoring, anomaly detection, and predictive analytics. These capabilities help teams identify issues before they impact users.
Cloud-native architectures also influence operational practices significantly. Containers, Kubernetes platforms, serverless computing, and distributed systems introduce new reliability challenges that require specialized expertise.
Additionally, observability continues expanding beyond traditional monitoring. Organizations seek deeper visibility into application behavior, infrastructure performance, and customer experiences.
As systems become more complex, reliability engineering will remain a critical discipline supporting business success and digital transformation initiatives.
FAQ Section
What is Site Reliability Engineering?
Site Reliability Engineering is a discipline that applies software engineering principles to IT operations to improve system reliability, scalability, and efficiency.
Is SRE only for large companies?
No. Organizations of all sizes can benefit from SRE principles because reliability challenges exist in both small and large environments.
Do I need programming skills for SRE?
Yes. Basic programming and scripting skills are important because automation plays a major role in modern reliability engineering.
What is the difference between DevOps and SRE?
DevOps focuses on collaboration and delivery practices, while SRE provides specific reliability-focused methods, metrics, and operational frameworks.
Which programming language is best for SRE?
Python is commonly recommended for beginners because it supports automation, scripting, monitoring integrations, and infrastructure management tasks.
How important is cloud knowledge for SRE?
Cloud knowledge is highly valuable because many modern applications operate on cloud platforms and distributed infrastructures.
What are SLOs in SRE?
Service Level Objectives are measurable reliability targets that define acceptable service performance levels.
Can beginners start learning SRE without operations experience?
Yes. Many professionals begin with Linux, networking, cloud computing, and automation fundamentals before progressing into advanced reliability engineering concepts.
Is Kubernetes mandatory for SRE careers?
Not always, but Kubernetes knowledge is increasingly valuable because many organizations deploy cloud-native applications using container orchestration platforms.
How long does it take to become proficient in SRE?
The timeline varies depending on prior experience, learning consistency, hands-on practice, and exposure to real-world operational environments.
Final Summary
Site Reliability Engineering has become one of the most important disciplines in modern technology organizations because it enables businesses to deliver reliable digital services while maintaining rapid innovation. By combining software engineering principles with operational expertise, SRE professionals help organizations achieve scalability, resilience, efficiency, and customer satisfaction.
Understanding concepts such as SLIs, SLOs, error budgets, observability, automation, incident management, and capacity planning provides a strong foundation for beginners entering the field. Additionally, recognizing the difference between technology platforms and organizational culture helps teams implement sustainable reliability practices.
Real-world applications across e-commerce, financial services, cloud computing, and media platforms demonstrate the practical value of SRE methodologies. At the same time, avoiding common mistakes such as inadequate monitoring, excessive manual work, poor documentation, and alert fatigue significantly improves operational effectiveness.