Introduction
AiOpsSchool equips technology professionals with the critical skills needed to conquer the complexities of modern, distributed cloud systems. Today’s engineering teams face a relentless onslaught of alert noise that routinely overwhelms traditional, static monitoring setups. This chaotic environments causes severe cognitive fatigue for on-call engineers while masking critical underlying infrastructure failures. By systematically infusing machine learning pipelines directly into your telemetry architecture, you eliminate manual troubleshooting guesswork entirely. Committing to a comprehensive AIOps Training program empowers your staff to build resilient, self-healing software ecosystems.
Transforming raw infrastructure metrics into clear, actionable system intelligence requires a deliberate strategy. Modern software teams must pivot away from reactive troubleshooting paradigms and embrace intelligent, algorithmic cluster monitoring. This proactive stance ensures your enterprise can maintain high application availability even during massive traffic spikes. Embracing these advanced automation methodologies secures your organization’s position at the absolute forefront of digital operational excellence.
Mastering the Architecture of Intelligent IT Infrastructure
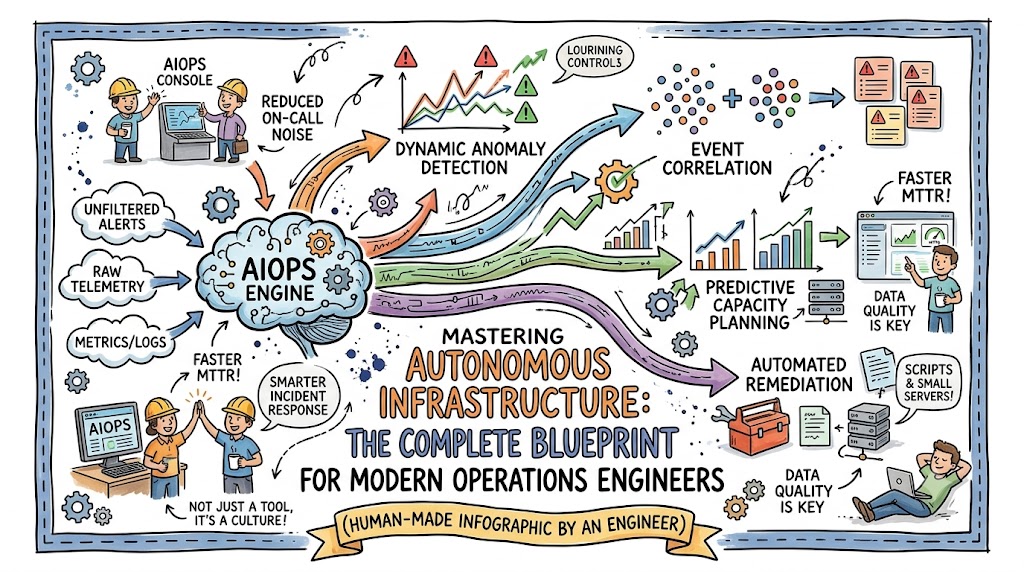
Artificial intelligence for IT operations unifies big data analytics, automated orchestration, and machine learning models into a single operational command center. This advanced discipline ingests vast quantities of infrastructure telemetry to identify hidden behavioral anomalies and trace system dependencies automatically. Instead of waiting for a component to fail, the system continuously analyzes trends to predict and prevent performance degradation. It acts as an autonomous brain that keeps your entire cloud ecosystem running at peak efficiency.
This methodology breaks down traditional engineering silos by synthesizing metrics, application logs, and distributed traces into a coherent story. The platform establishes a dynamic baseline of standard operational behavior, allowing it to instantly flag subtle performance deviations. Consequently, engineers no longer spend precious hours digging through disconnected dashboards during a production crisis. Moving to this intelligent model shifts your team’s focus from exhausting firefighting to strategic, long-term architecture optimization.
Key Operational Concepts You Must Know
Succeeding with AIOps in IT operations demands a rock-solid grasp of modern telemetry components and data analysis workflows. Mastery of these fundamental elements allows you to transform chaotic data streams into precise automated responses.
- Full-Stack Observability: The continuous analysis of external system outputs to accurately measure and understand internal application states across hybrid cloud environments.
- Unified Telemetry Data: The structured consolidation of numerical metrics, timestamped event logs, and end-to-end request traces into a single high-performance data lake.
- Intelligent Event Correlation: Advanced algorithmic clustering that groups thousands of isolated network alerts into a single, contextualized incident ticket.
- Dynamic Baseline vs. Anomaly: Statistical modeling that calculates normal system performance while adjusting for seasonal traffic patterns, ensuring highly accurate threat detection.
- Automated Remediation: The immediate execution of self-healing scripts and infrastructure adjustments to resolve active system anomalies without human intervention.
Navigating Your Path as a Beginner
Stepping into the world of algorithmic operations opens up a wealth of career opportunities, and AIOps for beginners serves as an ideal launchpad. The rapid evolution of corporate infrastructure makes this the perfect moment to cultivate these technical capabilities.
- Explosive Telemetry Volumes: Modern software platforms generate massive streams of operational data that completely surpass human manual analysis capabilities.
- Widespread Multi-Cloud Deployment: Organizations continue to expand across complex hybrid cloud architectures, creating a critical need for unified, intelligent management tools.
- The Industry Push for Automation: Enterprises actively prioritize engineers who know how to replace manual operations with scalable, autonomous software guardrails.
Comparative Framework Analysis
Differentiating between modern technical methodologies is essential for designing an effective corporate engineering strategy. The matrix below breaks down the unique scope and core focus of each practice.
| Concept | Primary Focus | Core Question It Answers |
|---|---|---|
| AIOps vs DevOps | Applying data science and machine learning to optimize enterprise infrastructure management. | How can we leverage artificial intelligence to automate incident workflows and maximize application uptime? |
| AIOps vs MLOps | Managing the lifecycle, deployment pipelines, and operational health of machine learning models. | How do we build dependable pipelines to train, deploy, and monitor our data science assets? |
| DevOps | Enhancing cross-team collaboration through automated software delivery and continuous integration. | How can we accelerate software feature releases while ensuring strict platform stability? |
Tool Integration versus Cultural Evolution
Engineering leaders often make the mistake of treating autonomous software as a simple plug-and-play platform. Achieving true reliability requires balancing advanced software installation with a deliberate shift in how your engineering teams collaborate.
| Operational Element | Platform Implementation | Cultural Transformation |
|---|---|---|
| Strategic Goal | Deploying monitoring agents and building cloud data pipelines. | Fostering team trust in automated infrastructure adjustments. |
| Core Execution Tasks | Connecting software APIs and normalizing unstructured log data. | Redefining operational roles and tearing down institutional data silos. |
| Primary Hurdle | Handling high-velocity data streams and retrofitting legacy environments. | Overcoming staff resistance to automated system healing. |
Focusing entirely on software purchases while neglecting your team’s internal workflows leads to abandoned tools and wasted capital. True operational breakthroughs happen when your engineers fully trust algorithmic insights and adapt their daily habits to support an automated ecosystem.
Core Operational Use Cases
Deploying intelligent automation directly targets and resolves the most persistent bottlenecks in enterprise infrastructure management. Engineering teams maintain unmatched system availability by executing these primary use cases:
- Dynamic Anomaly Detection: Scoring live system behavior against mathematical baselines to capture strange resource consumption patterns before downtime occurs.
- Automated Event Correlation: Condensing millions of frantic network pings and error logs into a handful of clear, actionable incident summaries.
- Advanced AIOps root cause analysis: Trailing systemic dependencies across complex microservice webs to locate the absolute source of an outage instantly.
- Predictive Capacity Planning: Examining historical infrastructure data to forecast compute, memory, and storage resource requirements months in advance.
- Instant Automated Remediation: Launching targeted self-healing scripts to reboot stuck processes or provision additional cloud resources dynamically.
- Maximizing AIOps in IT operations: Overhauling standard day-to-day maintenance workflows to move teams from reactive panic to calm, strategic platform scaling.
Real-World Operational Scenarios
In high-volume e-commerce environments, sudden microservice latency can instantly disrupt consumer checkout funnels and damage company revenue. By implementing targeted AIOps use cases, an online merchant can instantly map database execution spikes to a specific container failure. The platform routes checkout traffic to healthy clusters automatically, bypassing the issue and protecting customer transactions long before an engineer joins a triage call.
Global banking platforms process millions of secure financial exchanges every second while defending against sophisticated network threats. These institutions safeguard their AIOps in IT operations by configuring machine learning algorithms to continuously analyze network connection data. The moment the algorithm spots an irregular data export trend, it isolates the compromised virtual subnet, stopping data exfiltration before a human analyst can read the alert.
Enterprise Software-as-a-Service vendors face the constant challenge of managing volatile user workloads without overspending on cloud resources. By running predictive analytics models against historical compute trends, a SaaS operator can accurately forecast user traffic surges hours ahead of time. This insight allows the platform to scale its infrastructure upward proactively, ensuring flawless application performance while keeping cloud expenses highly optimized.
AIOps Tools You Should Know
Constructing a reliable, automated infrastructure requires selecting the right software stack for your team’s specific scaling requirements. The following breakdown lists the premier technologies dominant in the current enterprise market:
Full-Stack Monitoring and Observability Platforms
- Dynatrace: Combines deep observability with built-in machine learning to deliver automated root-cause analysis for large-scale systems.
- Datadog: Aggregates metrics, traces, and system logs into a unified, interactive cloud monitoring interface.
- New Relic: Equips engineers with comprehensive visualization capabilities to optimize application performance metrics.
- ScienceLogic: Focuses on cross-domain monitoring and automated workflow integration for hybrid cloud environments.
Intelligent Event Correlation and ITSM Tools
- BigPanda: Specializes in processing massive alert floods and clustering disparate notices into unified incident profiles.
- PagerDuty: Pairs digital operations orchestration with automated routing to accelerate response times.
- Moogsoft: Implements proprietary algorithms to strip out alert duplication and simplify incident management workflows.
Open-Source Telemetry Frameworks
- Prometheus & Grafana: The definitive open-source architecture for gathering time-series data and rendering interactive dashboards.
- OpenTelemetry: A vendor-agnostic framework designed to standardize the generation and collection of high-quality system telemetry.
Cloud-Native Operational Services
- AWS CloudWatch Anomaly Detection: Applies pre-trained machine learning algorithms to track and flag unusual deviations in cloud metrics.
Consulting a detailed AIOps Tutorial provides the practical code samples and configuration steps needed to blend these standalone tools into a powerful, self-healing system.
Common Pitfalls in System Automation
Adopting automated operations introduces specific challenges that can easily derail your team’s digital transformation if left unaddressed. Recognizing these engineering mistakes early keeps your infrastructure strategy on a direct path to success.
- Neglecting Alert Aggregation: Failing to configure intelligent deduplication filters allows minor background alerts to flood engineering channels. This oversight causes severe alert fatigue and leads staff to miss critical infrastructure warnings.
- Treating Machine Learning as Static: Assuming your operational models will remain accurate indefinitely without continuous tuning invites system failures. Teams must regularly retrain analytical engines with fresh telemetry data.
- Ignoring Telemetry Data Cleansing: Feeding poorly formatted, unparsed log structures into an AI engine generates unreliable conclusions. Technical leaders must enforce rigid data normalization standards across all software services.
- Deploying Auto-Remediation Prematurely: Activating automated self-healing scripts before validating your system models can trigger cascading infrastructure damage. Engineers must rigorously test remediation code inside isolated staging environments first.
- Failing to Secure Engineering Buy-In: Introducing complex automation tools without providing adequate instruction leads to fragmented tool adoption. Teams must champion shared education programs to build company-wide confidence in automated insights.
Elevating Site Reliability Engineering
Site Reliability Engineering centers on maximizing system availability while accelerating feature deployment pipelines. Integrating AIOps for SRE provides engineering squads with the deep predictive capabilities necessary to confidently defend strict Service Level Objectives.
+--------------------------------------------------------------+
| Intelligent SRE Workflow |
+--------------------------------------------------------------+
| |
| Telemetry Ingestion ---> Machine Learning Analytics |
| (Logs/Metrics/Traces) (Dynamic Baselining) |
| | |
| v |
| Automated Remediation <--- Root Cause Identified |
| (Self-Healing Scripts) (MTTD/MTTR Drastically Reduced) |
| |
+--------------------------------------------------------------+
Machine learning algorithms continuously assess real-time data trends to forecast impending Service Level Indicator breaches before users encounter an error. This early warning window gives SREs plenty of time to optimize resource allocation, which slashes Mean Time to Detection and Mean Time to Resolution metrics. Shifting away from chaotic manual troubleshooting frees engineers to build robust, long-term application frameworks.
Autonomous Resolution in Real-Time
Reviewing a real-world infrastructure scenario illustrates the immense practical difference between legacy monitoring and automated operations. This comparison details exactly how machine learning changes incident response.
The Production Outage
A high-traffic financial services portal suffers an unexpected, massive latency spike in its core payment processing application. The company’s old legacy monitoring system triggers hundreds of uncoordinated email alerts, triggering immediate panic across the on-call support team.
The Automated Response Workflow
- Ingestion: The centralized analytics engine gathers real-time telemetry from every database, server, and container.
- Correlation: The system suppresses thousands of duplicate alerts and organizes the core issue into a single, comprehensive incident ticket.
- Root Cause Identification: Utilizing smart AIOps root cause analysis, the platform identifies a slow, unindexed database query introduced during an application update.
- Remediation: The system automatically executes a pre-verified script to spin up an isolated database replica while alerting the developer on duty.
The Measurable Business Result
Optimizing AIOps in IT operations shrinks the enterprise’s Mean Time to Resolution from four agonizing hours down to under five minutes. This speed preserves the customer experience and shields the business from costly operational downtime penalties.
Technical Excellence Roadmap
Graduating into a skilled operations expert requires a logical, methodical plan to master both infrastructure engineering and practical data analytics. Following this structured pathway ensures you accumulate the hands-on experience demanded by enterprise software teams.
- Govern the Infrastructure Basics: Establish deep familiarity with Linux administration, core cloud networking concepts, and standard monitoring tools.
- Adopt Advanced Automation Tooling: Gain practical competency with container orchestration systems like Kubernetes and infrastructure-as-code software.
- Complete Specialized AIOps Training: Enroll in focused professional courses to master statistical anomaly detection models and automated event handling.
- Build Real-World Technical Projects: Design custom integrations using open-source telemetry libraries and modern event correlation software stacks.
- Secure an Industry AIOps Course Certificate: Validate your practical skills by earning professional credentials that demonstrate your technical competency to global employers.
Why Get an AIOps Certification?
Corporate operations are shifting rapidly away from manual observation, sparking a major surge in demand for certified automation professionals. Earning a verified AIOps Certification provides a massive career advantage in today’s technology employment market.
- Instant Professional Credibility: Presenting a verified certificate verifies your technical capability to implement AI-driven automation across distributed corporate systems.
- Structured Technical Curriculum: Completing a formal training track guarantees you master everything from initial telemetry collection to automated system healing.
- Enhanced Career Growth: Certified engineers hold significant leverage when interviewing for senior platform engineering, SRE, and DevOps positions.
Securing your AIOps Foundation Certification confirms your thorough understanding of the data science mechanics required to lead modern engineering initiatives.
Frequently Asked Questions
- How do traditional monitoring setups differ from AIOps?Standard monitoring utilities rely on rigid, pre-set thresholds to trigger warnings, forcing engineers to manually trace the source of every system problem. AIOps utilizes machine learning to ingest telemetry data, group related events automatically, and uncover the true origin of failures in real time.
- What career advantages come with completing an AIOps Certification?Earning an AIOps Certification proves your ability to deploy and manage automated cloud environments. This specialized credential captures the attention of enterprise recruiters and helps you transition into high-paying platform engineering and SRE roles.
- Which core concepts are covered in a premium AIOps Course?A well-designed AIOps Course teaches telemetry data normalization, algorithmic anomaly detection, automated event correlation, and self-healing workflow scripts. Students gain practical experience by configuring standard enterprise operations platforms.
- Is it feasible to complete AIOps Online Training while working a full-time job?Yes, elite educational platforms deliver flexible, self-paced online courses structured explicitly to accommodate busy technology professionals. This setup lets you build advanced automation skills without interrupting your current employment schedule.
- Why should an established DevOps veteran pursue an AIOps Foundation Certification?An AIOps Foundation Certification confirms your mastery of the data analytics and machine learning principles that govern modern automated infrastructure. It establishes your technical authority before you lead large-scale enterprise automation projects.
- What clear strategic goals does an AIOps Consulting engagement fulfill?Consulting teams assess your existing infrastructure maturity, help you select optimal machine learning tools, and outline scalable data aggregation strategies. This professional oversight reduces architectural risks and accelerates your company’s automation timeline.
- How do enterprise AIOps Implementation Services reduce operational friction?These deployment services handle everything from building complex data collection pipelines to coding automated incident resolution workflows. This expert support frees your internal developers to focus entirely on building core application features.
- What sets AI Observability Training apart from basic monitoring classes?This specific curriculum teaches engineers how to observe and debug non-deterministic machine learning models and large language model workflows in production. Students learn to trace data drift, calculate token latency, and ensure model quality.
Technical Education Programs
Developing the skills necessary to run autonomous cloud systems requires a targeted, practical training framework. Engineers can access a robust selection of educational programs tailored to meet their specific professional goals.
- AIOps Training: Immersive, hands-on educational tracks focused on deploying machine learning algorithms and constructing automated remediation workflows.
- AIOps Course: Deep-dive academic modules teaching telemetry normalization techniques and advanced event grouping strategies.
- AIOps Certification: Industry-validated credentials that certify your engineering competence, paving the way to senior infrastructure leadership roles.
- AIOps Tutorial: Direct, code-focused guides that offer immediate practice setting up open-source telemetry pipelines and self-healing scripts.
Final Thoughts
Legacy monitoring tools can no longer protect modern enterprises from the staggering complexity of distributed microservices and multi-cloud platforms. Success in today’s tech market requires engineering teams to adopt intelligent software systems that resolve infrastructure failures before they damage the user experience. Advancing your career in this landscape requires a dedicated commitment to learning modern data analytics and automation workflows. Completing structured AIOps Training gives you the precise technical tools needed to pioneer self-healing infrastructure. Earning an authorized AIOps Certification establishes your professional authority and showcases your ability to lead complex corporate operations. Head over to AiOpsSchool.com to explore their advanced educational catalogs and unlock your full potential as an operations innovator.