Modern software systems have become more complex than ever. Organizations deploy applications frequently, manage distributed infrastructure, support global users, and handle massive amounts of data. As a result, the traditional separation between development teams and operations teams often creates challenges. Developers focus on building features and delivering business value, while operations teams concentrate on maintaining stability, performance, and availability. When these objectives are not aligned, organizations experience delays, communication gaps, deployment failures, and operational inefficiencies.
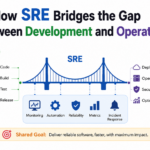
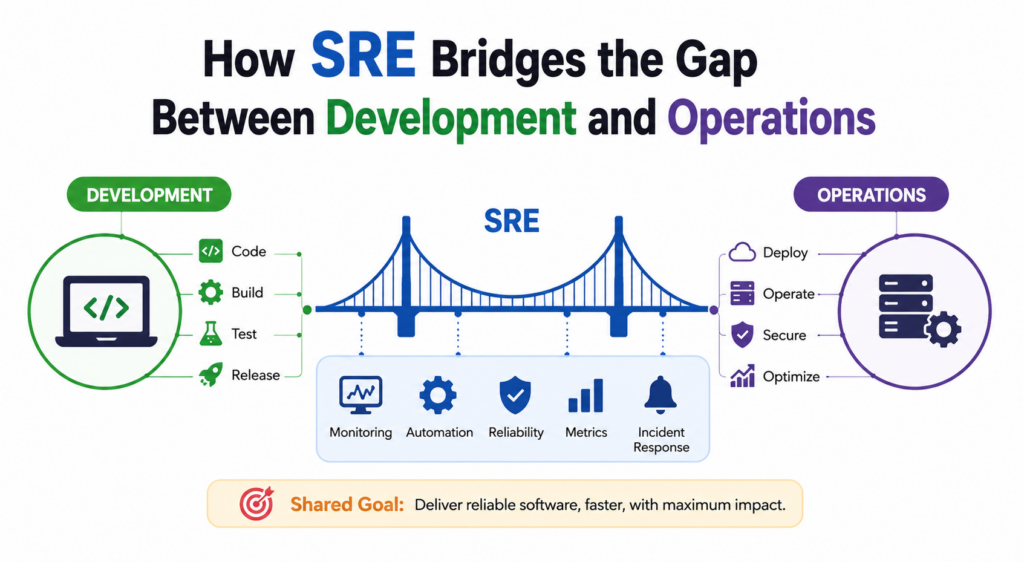
This is where Site Reliability Engineering (SRE) plays a critical role. SRE creates a practical framework that combines software engineering principles with operational excellence. Instead of treating development and operations as separate functions, SRE encourages collaboration, shared responsibility, automation, and measurable reliability goals. Through continuous improvement and data-driven decision-making, SRE helps organizations achieve both innovation and stability.
Professionals who want to master these concepts often explore advanced learning platforms such as Sreschool, where they can gain practical knowledge about reliability engineering, automation, monitoring, incident response, and modern operational practices. Understanding how SRE bridges the gap between development and operations helps organizations deliver better software, improve customer experiences, and build highly reliable digital services.
Understanding the Relationship Between Development and Operations
For many years, development and operations teams worked independently. Developers created software, completed coding tasks, and handed applications over to operations teams for deployment and maintenance. While this model appeared efficient on paper, it often introduced delays and misunderstandings. Developers prioritized rapid feature delivery, whereas operations engineers focused on minimizing risks and ensuring system stability.
As organizations scaled, this separation became increasingly problematic. Developers lacked visibility into production environments, while operations teams struggled to understand application design decisions. Consequently, incidents became harder to resolve, deployment cycles slowed down, and accountability often became unclear. Teams frequently blamed one another when failures occurred, creating organizational friction.
SRE addresses this challenge by creating shared ownership. Reliability becomes a collective responsibility rather than the sole responsibility of operations teams. Developers gain greater visibility into production systems, and operations professionals leverage engineering practices to automate repetitive tasks. This collaborative approach reduces friction and creates a healthier operational environment where innovation and reliability can coexist effectively.
What Is Site Reliability Engineering?
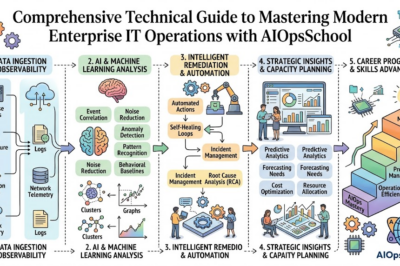
Site Reliability Engineering is a discipline that applies software engineering techniques to operational challenges. Instead of relying heavily on manual processes, SRE teams build automation, monitoring systems, deployment pipelines, and reliability frameworks that improve system performance and availability.
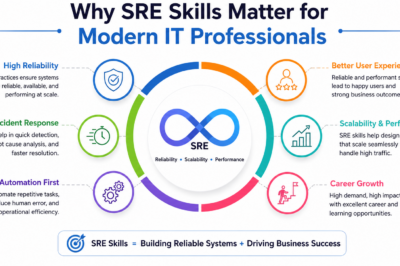
The core philosophy behind SRE is that reliability should be measurable and manageable. Organizations define clear service objectives and continuously monitor system performance against those objectives. Teams use data to make informed decisions regarding releases, infrastructure improvements, incident management, and operational priorities.
SRE also encourages balancing innovation with stability. While businesses need rapid feature delivery to remain competitive, they must also maintain reliable systems for customers. Through concepts such as Service Level Indicators (SLIs), Service Level Objectives (SLOs), and error budgets, SRE provides a structured way to manage this balance. As a result, organizations can innovate confidently without compromising operational excellence.
Why Organizations Need SRE Today
Modern digital businesses operate in highly dynamic environments. Applications run across cloud platforms, microservices architectures, containers, distributed databases, and global networks. Managing these systems manually is no longer practical. Organizations require sophisticated operational frameworks that can support rapid growth while maintaining reliability.
SRE helps organizations address these challenges by introducing engineering discipline into operations. Automation reduces manual effort and human error. Monitoring systems provide visibility into performance and availability. Incident management processes improve response times during outages. Capacity planning helps organizations prepare for growth before performance issues arise.
Additionally, customer expectations continue to increase. Users expect applications to be available at all times and perform consistently regardless of location or workload. Even brief outages can affect customer trust and business revenue. By implementing SRE practices, organizations can proactively manage reliability, improve user experiences, and reduce operational risks across complex environments.
Key Operational Concepts You Must Know
Understanding SRE requires familiarity with several foundational operational concepts. These principles form the basis of reliability engineering and help teams make informed decisions regarding system performance, availability, and scalability.
Service Level Indicators (SLIs)
Service Level Indicators are measurable metrics that reflect service performance from the user’s perspective. Common examples include response time, error rate, availability, latency, and throughput. SLIs provide objective data that helps teams evaluate system health and reliability.
Rather than relying on assumptions, organizations use SLIs to understand actual service performance. These metrics help teams identify trends, detect issues early, and evaluate the impact of operational changes. Accurate measurement creates transparency and enables continuous improvement across both development and operations functions.
Service Level Objectives (SLOs)
Service Level Objectives define reliability targets that services should achieve. An SLO may specify that an application should maintain a certain level of availability or response time over a defined period. These objectives align technical performance with business expectations.
Well-designed SLOs help teams prioritize work effectively. When reliability falls below acceptable thresholds, teams focus on operational improvements. When objectives are consistently achieved, teams can safely invest more effort into innovation and feature development.
Error Budgets
Error budgets represent the acceptable amount of unreliability a service can experience while still meeting its SLOs. This concept creates a practical balance between development speed and operational stability.
If a service exceeds its error budget, teams prioritize reliability improvements before introducing additional changes. Conversely, if sufficient budget remains available, development teams can continue delivering new features confidently. This approach eliminates subjective debates and encourages data-driven decision-making.
Observability
Observability enables teams to understand system behavior through metrics, logs, and traces. Modern applications generate enormous amounts of operational data, making observability essential for troubleshooting and performance optimization.
Strong observability practices provide visibility into distributed systems and complex dependencies. Engineers can quickly identify root causes, understand system interactions, and resolve issues efficiently. Improved observability reduces downtime and enhances operational effectiveness.
Incident Management
Incidents are inevitable in complex environments. Effective incident management processes help organizations detect, respond to, and recover from service disruptions quickly.
SRE teams establish clear procedures for incident response, escalation, communication, and post-incident analysis. These structured approaches reduce confusion during critical situations and promote continuous learning after incidents occur.
Platform Implementation vs. Culture — What’s the Real Difference?
Many organizations assume that implementing new tools automatically improves operational performance. While platforms and technologies play an important role, culture often determines whether SRE initiatives succeed or fail. Understanding the distinction between implementation and culture is essential for sustainable operational excellence.
Platform Implementation
Platform implementation focuses on technical capabilities. Organizations deploy monitoring solutions, automation frameworks, CI/CD pipelines, infrastructure management tools, observability platforms, and incident response systems. These technologies improve efficiency and provide valuable operational insights.
Modern platforms help teams automate repetitive tasks, reduce deployment risks, improve visibility, and manage infrastructure at scale. Technical implementation establishes the foundation needed to support reliable operations. However, technology alone cannot solve organizational challenges.
Without proper adoption and collaboration, even advanced platforms may deliver limited value. Teams might continue operating in silos, ignore operational metrics, or resist process improvements despite having powerful tools available.
Operational Culture
Culture defines how people work together, share responsibility, communicate, and solve problems. Successful SRE organizations promote collaboration between developers and operations teams. Reliability becomes a shared objective rather than an isolated responsibility.
Strong operational cultures encourage learning, transparency, accountability, and continuous improvement. Teams conduct blameless postmortems after incidents, openly discuss failures, and focus on systemic improvements instead of individual mistakes.
When organizations prioritize culture alongside technology, they create environments where operational excellence can thrive. Employees become more engaged, collaboration improves, and reliability initiatives generate lasting business value.
The Real Difference
The fundamental difference lies in sustainability. Platforms provide capabilities, while culture determines how effectively those capabilities are used. Organizations that invest exclusively in tools often struggle to achieve meaningful improvements. Conversely, organizations that combine technical implementation with cultural transformation create resilient operational ecosystems.
SRE succeeds when technology and culture work together. Automation, monitoring, and deployment platforms enable efficiency, while collaborative cultures ensure those tools support shared goals and continuous improvement.
Real-World Use Cases of Modern Operations
Modern operations teams leverage SRE principles across a wide range of scenarios. These practical applications demonstrate how reliability engineering delivers measurable business value while supporting innovation and growth.
Continuous Deployment at Scale
Organizations that release software frequently require reliable deployment processes. SRE teams build automated pipelines that validate code, execute tests, and deploy changes safely across environments.
Automation reduces manual intervention and minimizes deployment risks. Rollback mechanisms, canary releases, and progressive delivery techniques allow organizations to introduce changes confidently while maintaining service reliability. As a result, development teams can innovate faster without compromising operational stability.
Managing Cloud Infrastructure
Cloud environments offer flexibility and scalability, but they also introduce operational complexity. SRE teams use Infrastructure as Code, automation frameworks, and monitoring platforms to manage cloud resources efficiently.
Automated provisioning improves consistency and reduces configuration drift. Continuous monitoring helps identify performance bottlenecks and capacity constraints before they affect users. These practices support scalable and reliable cloud operations.
Incident Response and Recovery
When outages occur, rapid response becomes critical. SRE teams implement alerting systems, incident management workflows, and recovery procedures that minimize downtime.
Engineers use observability tools to diagnose issues quickly and coordinate responses across teams. Structured communication processes keep stakeholders informed throughout incident resolution. These capabilities improve organizational resilience and customer satisfaction.
Capacity Planning
Growing applications must accommodate increasing workloads without degrading performance. SRE teams analyze usage patterns, forecast future demand, and optimize infrastructure capacity proactively.
Capacity planning prevents resource shortages and ensures consistent user experiences during periods of growth. Organizations avoid costly emergency upgrades while maintaining operational efficiency.
Security and Reliability Integration
Security and reliability often intersect in modern environments. SRE teams collaborate with security professionals to implement automated controls, vulnerability monitoring, and secure operational practices.
By integrating security into operational workflows, organizations reduce risks while maintaining service availability. This alignment supports comprehensive operational excellence across technology environments.
Common Mistakes in Operations Engineering
Despite access to advanced technologies and methodologies, organizations often encounter recurring operational challenges. Recognizing these mistakes helps teams avoid costly disruptions and improve reliability outcomes.
Relying Too Heavily on Manual Processes
Manual operations create inefficiencies and increase the likelihood of human error. Tasks such as deployments, configuration management, and infrastructure provisioning become difficult to scale when performed manually.
Automation reduces operational burden and improves consistency. Organizations that prioritize automation can respond more effectively to changing business requirements while maintaining reliability standards.
Ignoring Observability
Many teams implement monitoring but fail to establish comprehensive observability. Limited visibility makes troubleshooting difficult and delays incident resolution.
Organizations should invest in metrics, logs, traces, dashboards, and alerting systems that provide meaningful operational insights. Strong observability enables proactive problem detection and faster recovery.
Setting Unrealistic Reliability Targets
Overly ambitious reliability goals can create unnecessary pressure and divert resources from other priorities. Teams should establish realistic objectives that align with business needs and technical capabilities.
Balanced SLOs encourage sustainable improvement while maintaining focus on customer outcomes. Effective reliability management requires practical targets rather than perfection.
Poor Incident Reviews
Some organizations treat incidents as isolated events rather than learning opportunities. Without thorough post-incident analysis, recurring issues continue affecting service reliability.
Blameless postmortems help teams identify root causes, improve processes, and strengthen operational resilience. Continuous learning is essential for long-term success.
Lack of Cross-Team Collaboration
Operational success depends on effective communication between development, operations, security, and business teams. Silos create misunderstandings and slow problem resolution.
Organizations should encourage collaboration, shared goals, and transparent communication across all functions. Strong partnerships improve decision-making and operational outcomes.
How to Become an Operations Expert — Career Roadmap
Building expertise in operations engineering and SRE requires a combination of technical knowledge, practical experience, and continuous learning. Professionals who follow a structured development path can create rewarding careers in modern technology environments.
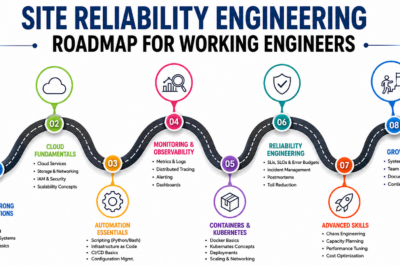
Step 1: Build Strong Technical Foundations
Start by developing knowledge of operating systems, networking, databases, cloud platforms, and scripting languages. Understanding infrastructure fundamentals creates a strong foundation for advanced operational concepts.
Focus on practical skills rather than theoretical knowledge alone. Hands-on experience accelerates learning and improves problem-solving capabilities.
Step 2: Learn Automation and Infrastructure Management
Automation is central to modern operations. Learn scripting, Infrastructure as Code, configuration management, and deployment automation techniques.
Key learning areas include:
- Linux administration
- Shell scripting
- Python programming
- Infrastructure as Code
- CI/CD pipelines
- Container technologies
- Cloud platforms
These skills help professionals manage large-scale environments efficiently.
Step 3: Develop Monitoring and Observability Skills
Understanding system behavior is critical for operational success. Learn how to collect, analyze, and interpret operational data effectively.
Focus on:
- Metrics collection
- Log analysis
- Distributed tracing
- Alert management
- Dashboard creation
- Incident investigation
Strong observability skills enable faster troubleshooting and proactive reliability management.
Step 4: Master Reliability Engineering Concepts
Study core SRE principles including SLOs, SLIs, error budgets, incident response, and capacity planning. These concepts help professionals balance innovation with operational stability.
Practical implementation experience strengthens understanding and prepares engineers for complex operational environments.
Step 5: Improve Communication and Leadership Skills
Technical expertise alone is insufficient for operational leadership. Successful operations experts communicate effectively, facilitate collaboration, and drive organizational improvements.
Develop skills in:
- Incident coordination
- Stakeholder communication
- Team collaboration
- Documentation
- Problem-solving
- Decision-making
These capabilities enhance career growth and professional impact.
Operations Career Progression
| Career Stage | Primary Focus |
|---|---|
| Junior Engineer | Infrastructure fundamentals and support |
| Systems Administrator | Platform management and automation |
| DevOps Engineer | CI/CD and infrastructure automation |
| SRE Engineer | Reliability engineering and observability |
| Senior SRE | Architecture and operational strategy |
| Reliability Manager | Team leadership and governance |
| Operations Director | Enterprise operational excellence |
Consistent learning and hands-on practice support progression through each stage.
FAQ Section
What is the main purpose of SRE?
The primary purpose of SRE is to improve system reliability by applying software engineering practices to operational challenges while balancing innovation and stability.
How does SRE differ from traditional operations?
Traditional operations often rely on manual processes, whereas SRE emphasizes automation, measurable reliability objectives, and engineering-driven solutions.
Why are SLOs important in SRE?
SLOs provide clear reliability targets that help teams prioritize work, evaluate performance, and make data-driven decisions.
Can small organizations benefit from SRE?
Yes. Even small organizations can improve reliability, deployment efficiency, and operational visibility by adopting SRE principles gradually.
Is coding required for SRE roles?
Yes. SRE professionals frequently use programming and scripting to automate processes, manage infrastructure, and build operational tools.
What tools are commonly used in SRE?
Common tools include monitoring platforms, observability solutions, CI/CD systems, cloud services, container platforms, and Infrastructure as Code frameworks.
How does SRE improve collaboration?
SRE promotes shared ownership, transparent communication, and common reliability goals that align development and operations teams.
What is an error budget?
An error budget represents the acceptable amount of service unreliability allowed while still meeting established service level objectives.
Does SRE replace DevOps?
No. SRE complements DevOps by providing practical frameworks and measurable approaches for achieving reliability goals.
What career opportunities exist in SRE?
Professionals can pursue roles such as SRE Engineer, Reliability Architect, Platform Engineer, DevOps Engineer, Operations Manager, and Reliability Leader.
Final Summary
Site Reliability Engineering has fundamentally changed how organizations approach software delivery and operational excellence. By combining software engineering practices with operational responsibilities, SRE successfully bridges the long-standing gap between development and operations teams. Instead of creating separate objectives and competing priorities, SRE establishes shared ownership, measurable reliability targets, and collaborative workflows that align technical efforts with business goals.
Organizations benefit from improved deployment efficiency, stronger system reliability, enhanced observability, faster incident response, and more effective capacity planning. At the same time, developers gain greater visibility into production systems, while operations teams leverage automation to eliminate repetitive tasks and reduce human error. This balance allows businesses to innovate rapidly without sacrificing stability.
As technology environments continue growing in complexity, SRE provides a structured framework for managing reliability at scale. Professionals who invest in automation, observability, cloud technologies, incident management, and reliability engineering principles position themselves for long-term success. Whether an organization is beginning its operational transformation or refining mature processes, SRE offers practical strategies that help teams deliver reliable, scalable, and high-performing services while fostering a culture of continuous improvement and shared responsibility.