Introduction
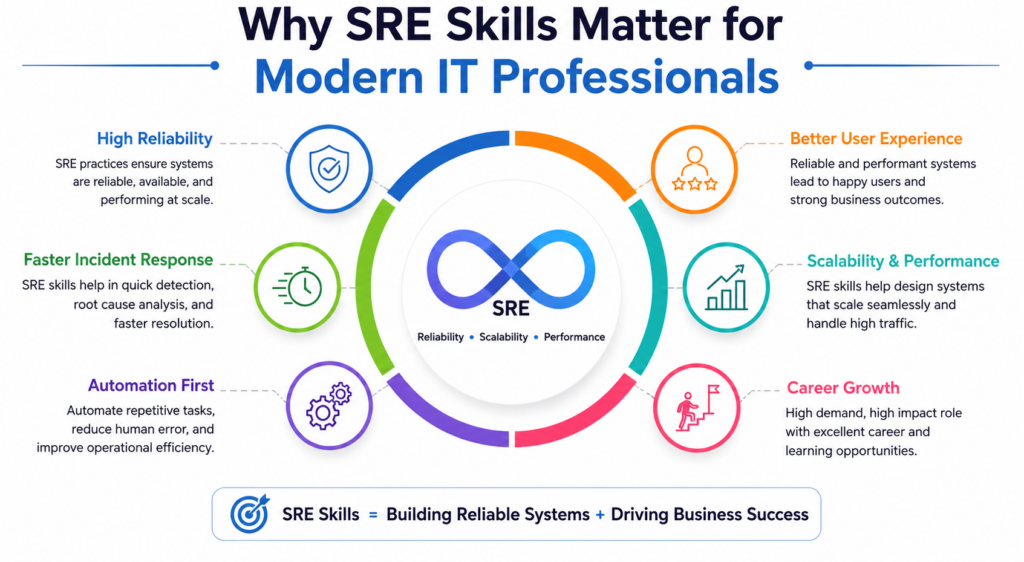
Modern businesses depend on digital services every minute of the day. Customers expect applications to load quickly, transactions to complete without errors, and platforms to remain available around the clock. As a result, organizations need professionals who can maintain reliability while supporting rapid innovation. This is where Site Reliability Engineering, commonly known as SRE, becomes extremely valuable.
SRE combines software engineering practices with IT operations to create reliable, scalable, and efficient systems. Instead of relying only on manual operational tasks, SRE professionals use automation, monitoring, observability, and engineering principles to manage infrastructure and services. Consequently, organizations can release new features faster while maintaining system stability.
For professionals who want to build strong careers in cloud computing, DevOps, platform engineering, infrastructure management, or software operations, SRE skills provide a significant advantage. They help teams reduce downtime, improve performance, strengthen customer experience, and manage complex systems effectively.
Many professionals learn these practices through specialized training programs offered by Sreschool, where they gain practical knowledge about reliability engineering, monitoring, automation, incident management, and operational excellence.
Why Modern Organizations Need SRE Skills
Technology environments have changed dramatically. Applications no longer run on a single server in a data center. Instead, they operate across cloud platforms, containers, microservices, APIs, databases, and distributed systems. While this architecture offers flexibility and scalability, it also introduces complexity.
Traditional operations teams often struggle to manage this complexity using manual processes. Even small configuration mistakes can affect thousands of users. Therefore, organizations need engineers who understand automation, reliability, monitoring, and system behavior.
SRE professionals focus on maintaining service reliability while supporting business growth. They create processes that reduce operational risk and help teams respond quickly when issues occur. Rather than constantly reacting to problems, they build systems that prevent many issues from happening in the first place.
Businesses also face increasing customer expectations. Users rarely tolerate service interruptions, slow response times, or poor digital experiences. Because of this, reliability directly impacts customer satisfaction, brand reputation, and revenue generation.
SRE practices help organizations balance innovation and stability. Development teams can release features more frequently while operations teams maintain service quality. This balance creates a competitive advantage in today’s technology-driven environment.
Furthermore, cloud adoption continues to increase across industries. As infrastructure becomes more dynamic, organizations need professionals who understand automated operations, capacity planning, observability, and incident response. SRE skills provide exactly these capabilities.
The Evolution from Traditional Operations to SRE
Traditional operations teams primarily focused on maintaining servers, networks, and infrastructure. Their success often depended on keeping systems running and minimizing disruptions. While these responsibilities remain important, modern environments require additional capabilities.
Applications now change rapidly. Development teams deploy updates frequently, infrastructure scales automatically, and services interact across multiple platforms. Manual operational approaches cannot keep pace with this level of complexity.
SRE emerged as a response to these challenges. Instead of separating development and operations, SRE combines software engineering techniques with operational responsibilities. Engineers write code to automate repetitive tasks, manage infrastructure programmatically, and improve system reliability.
This shift transforms operations from a reactive discipline into a proactive engineering function. Rather than manually resolving recurring issues, SRE teams build tools and systems that eliminate those issues permanently.
The result is greater efficiency, reduced operational burden, improved reliability, and faster innovation. Organizations benefit from lower downtime, better customer experiences, and stronger operational performance.
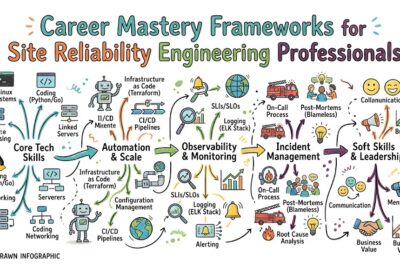
Key Operational Concepts You Must Know
Understanding core operational concepts forms the foundation of successful reliability engineering. These concepts guide decision-making, system design, and operational practices.
Reliability
Reliability measures a system’s ability to perform consistently under expected conditions. Reliable systems deliver predictable performance and maintain availability even during challenging situations.
Organizations prioritize reliability because service disruptions directly affect customers and business outcomes. SRE professionals continuously improve reliability through monitoring, automation, testing, and engineering improvements.
Reliable systems do not happen by accident. Teams must design, measure, and maintain reliability throughout the entire service lifecycle.
Availability
Availability refers to the percentage of time a service remains accessible and functional for users. High availability requires resilient architectures, redundancy, failover mechanisms, and effective operational practices.
SRE teams monitor availability metrics closely because they directly reflect customer experience. Even short outages can create significant business impact.
Maintaining availability requires constant attention to infrastructure health, application performance, network connectivity, and operational readiness.
Service Level Indicators (SLIs)
SLIs measure specific aspects of service performance. Examples include response time, request success rate, error rate, and system latency.
These measurements provide objective insights into service health. Instead of relying on assumptions, teams use SLIs to understand actual user experience.
Accurate indicators help organizations identify performance trends and prioritize improvements effectively.
Service Level Objectives (SLOs)
SLOs define target performance levels for services. They establish measurable reliability goals that align technical operations with business expectations.
For example, a service might target a specific availability percentage or response time threshold. These objectives help teams make informed decisions regarding deployments, maintenance, and risk management.
Well-defined objectives create clarity across development, operations, and business stakeholders.
Error Budgets
Error budgets represent the acceptable amount of service unreliability within a defined period.
Rather than pursuing perfect reliability, organizations balance innovation and stability. If services remain within budget limits, teams can continue releasing features aggressively. If reliability declines, teams focus on operational improvements.
This approach creates a healthy balance between development speed and operational excellence.
Monitoring
Monitoring involves collecting and analyzing system data to identify performance issues, failures, and operational trends.
Effective monitoring provides visibility into infrastructure, applications, databases, networks, and user interactions. Teams use monitoring systems to detect anomalies before they affect customers.
Strong monitoring practices form the foundation of modern operational excellence.
Observability
Observability extends beyond monitoring. It enables teams to understand internal system behavior through metrics, logs, traces, and telemetry data.
Modern distributed systems generate enormous amounts of operational information. Observability helps engineers investigate complex issues efficiently.
Without observability, troubleshooting becomes slow, reactive, and inefficient.
Incident Management
Incidents occur when services experience disruptions or degraded performance. Effective incident management minimizes customer impact and accelerates recovery.
SRE teams establish clear procedures for detection, communication, escalation, investigation, and resolution.
Well-structured incident management improves operational maturity and organizational resilience.
Automation
Automation eliminates repetitive manual tasks and reduces human error.
SRE professionals automate deployments, infrastructure provisioning, monitoring configuration, security checks, backups, and operational workflows.
Automation improves consistency, scalability, efficiency, and reliability across environments.
Capacity Planning
Capacity planning ensures systems can handle current and future demand.
Engineers analyze usage trends, infrastructure utilization, and growth projections to prevent resource shortages.
Proper planning helps organizations maintain performance while controlling operational costs.
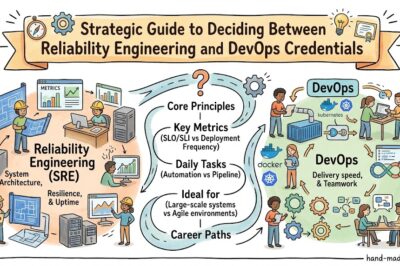
Platform Implementation vs. Culture — What’s the Real Difference?
Many organizations focus heavily on technology platforms when adopting modern operations practices. While tools and platforms are important, culture often determines long-term success.
Understanding the distinction between platform implementation and operational culture is essential for IT professionals.
What Is Platform Implementation?
Platform implementation involves deploying tools, infrastructure, and technical systems that support operational objectives.
Examples include:
- Monitoring platforms
- Observability tools
- CI/CD pipelines
- Container orchestration systems
- Infrastructure automation frameworks
- Incident management platforms
- Configuration management systems
These technologies improve efficiency and provide capabilities required for modern operations.
However, tools alone cannot guarantee operational excellence.
What Is Operational Culture?
Operational culture refers to the behaviors, values, processes, and collaboration patterns that guide teams.
A strong operational culture emphasizes:
- Shared ownership
- Continuous improvement
- Learning from failures
- Collaboration between teams
- Transparency
- Accountability
- Automation-first thinking
- Customer-focused decision-making
Culture influences how teams use technology and respond to challenges.
Why Technology Alone Is Not Enough
Organizations sometimes invest heavily in advanced platforms while neglecting cultural transformation.
As a result, teams may possess excellent tools but continue working with outdated processes and communication methods.
For example, a company may implement sophisticated monitoring systems yet fail to establish clear incident response procedures. Consequently, operational issues remain difficult to manage despite technological investments.
Successful operations require both technical capabilities and collaborative practices.
The Role of Shared Ownership
Traditional organizations often separate development and operations responsibilities.
This separation can create communication gaps and conflicting priorities. Developers focus on feature delivery, while operations teams focus on stability.
Modern operational culture encourages shared ownership. Teams collaborate throughout the service lifecycle and collectively support reliability goals.
This approach improves communication, accountability, and customer outcomes.
Continuous Improvement Mindset
Operations excellence depends on ongoing improvement.
Rather than assigning blame after incidents, mature organizations analyze root causes and identify opportunities for enhancement.
This learning-focused approach strengthens systems, processes, and team capabilities over time.
Building a Reliability Culture
Reliability culture develops when organizations consistently prioritize service quality and operational excellence.
Key characteristics include:
- Data-driven decisions
- Proactive problem solving
- Strong documentation
- Automated workflows
- Regular reviews
- Knowledge sharing
- Continuous learning
These practices create sustainable operational success.
Real-World Use Cases of Modern Operations
Modern operational practices support organizations across industries and technology environments.
The following examples demonstrate how reliability engineering creates measurable business value.
E-Commerce Platforms
Online retail platforms experience significant traffic fluctuations during promotions, product launches, and seasonal events.
SRE practices help organizations:
- Scale infrastructure automatically
- Monitor transaction performance
- Prevent service disruptions
- Maintain checkout reliability
- Reduce latency during peak demand
As a result, customers enjoy smooth shopping experiences even during high-traffic periods.
Banking and Financial Services
Financial institutions require exceptional reliability because service interruptions can affect transactions, customer trust, and regulatory compliance.
Operational teams use reliability engineering practices to:
- Monitor transaction systems
- Detect anomalies rapidly
- Improve disaster recovery readiness
- Enhance system resilience
- Reduce operational risk
These capabilities support secure and dependable financial services.
Cloud Service Providers
Cloud platforms operate massive distributed infrastructures supporting millions of users and applications.
Reliability engineers help maintain:
- Service availability
- Infrastructure health
- Resource utilization
- Security operations
- Global scalability
Without advanced operational practices, managing these environments would become extremely difficult.
Healthcare Systems
Healthcare organizations depend on reliable technology for patient records, diagnostics, communication, and operational workflows.
System outages can directly affect patient care.
Reliability-focused operations improve:
- Application availability
- Data accessibility
- Infrastructure resilience
- Performance consistency
- Operational continuity
These improvements support better healthcare delivery.
Media and Streaming Platforms
Streaming services experience unpredictable traffic patterns driven by popular content releases and live events.
Operational teams use monitoring, observability, and automated scaling to maintain service quality during demand spikes.
Customers receive uninterrupted viewing experiences while organizations optimize infrastructure utilization.
Telecommunications
Telecommunication providers manage extensive infrastructure supporting communication services.
Modern operational practices help maintain:
- Network reliability
- Service performance
- Incident response efficiency
- Capacity optimization
- Operational visibility
These capabilities support critical communication services worldwide.
Software-as-a-Service Companies
SaaS businesses depend heavily on service reliability because customers access applications continuously.
Reliability engineering helps these organizations:
- Reduce downtime
- Improve user experience
- Accelerate feature delivery
- Manage infrastructure growth
- Maintain customer satisfaction
Reliable services contribute directly to customer retention and business growth.
Common Mistakes in Operations Engineering
Many organizations encounter operational challenges because they overlook fundamental engineering principles.
Understanding these common mistakes helps professionals avoid costly problems.
Overreliance on Manual Processes
Manual operations create inconsistency and increase the likelihood of human error.
As environments grow, manual tasks become increasingly difficult to manage.
Organizations should automate repetitive workflows whenever possible.
Ignoring Monitoring Until Problems Occur
Some teams implement monitoring only after experiencing significant outages.
This reactive approach limits visibility and delays issue detection.
Monitoring should be established proactively before services enter production.
Focusing Only on Infrastructure
Infrastructure remains important, but customer experience depends on the entire technology stack.
Teams should monitor applications, databases, APIs, user interactions, and business metrics alongside infrastructure resources.
Lack of Documentation
Poor documentation slows troubleshooting and knowledge transfer.
Operational procedures, architectural decisions, incident responses, and system dependencies should remain well documented.
Comprehensive documentation improves consistency and operational efficiency.
Blame-Oriented Incident Reviews
Blame-focused cultures discourage transparency and learning.
Instead, organizations should conduct objective reviews that identify systemic improvements.
Learning-oriented reviews strengthen reliability and foster collaboration.
Ignoring Technical Debt
Technical debt accumulates when organizations prioritize short-term delivery over long-term maintainability.
Over time, excessive debt increases operational complexity and reliability risks.
Teams should address technical debt regularly to maintain healthy systems.
Weak Capacity Planning
Insufficient capacity planning can lead to performance degradation during growth periods.
Regular forecasting and utilization analysis help organizations prepare for future demand effectively.
Limited Observability
Without comprehensive observability, engineers struggle to understand complex system behavior.
Organizations should invest in logs, metrics, traces, and telemetry capabilities to improve troubleshooting efficiency.
Poor Incident Communication
During incidents, unclear communication creates confusion and delays recovery efforts.
Teams need structured communication processes that keep stakeholders informed throughout the response lifecycle.
Treating Reliability as Someone Else’s Responsibility
Reliability should be a shared organizational objective.
When teams collaborate around reliability goals, operational performance improves significantly.
How to Become an Operations Expert — Career Roadmap
Building expertise in operations engineering requires a combination of technical knowledge, practical experience, and continuous learning.
The following roadmap provides a structured path for aspiring professionals.
Step 1: Build Strong Technical Foundations
Start by understanding:
- Operating systems
- Networking concepts
- Linux administration
- Databases
- Cloud computing fundamentals
- Security basics
These foundational skills support more advanced operational responsibilities.
Step 2: Learn Programming and Automation
Modern operations rely heavily on automation.
Focus on learning:
- Python
- Shell scripting
- Infrastructure automation concepts
- API integration
- Configuration management
Programming enables engineers to automate repetitive tasks and improve efficiency.
Step 3: Understand Cloud Platforms
Cloud environments dominate modern infrastructure.
Gain practical experience with:
- Compute services
- Storage systems
- Networking services
- Identity management
- Monitoring tools
Cloud expertise significantly increases career opportunities.
Step 4: Master Monitoring and Observability
Develop skills in:
- Metrics collection
- Logging systems
- Distributed tracing
- Alert management
- Performance analysis
These capabilities form the core of reliability engineering.
Step 5: Learn Infrastructure as Code
Infrastructure as Code improves consistency and scalability.
Professionals should understand:
- Version-controlled infrastructure
- Automated provisioning
- Environment management
- Deployment automation
These practices support efficient infrastructure operations.
Step 6: Study Incident Management
Operational excellence requires effective incident response.
Learn how to:
- Detect incidents
- Coordinate responses
- Escalate appropriately
- Communicate effectively
- Conduct post-incident reviews
Strong incident management skills distinguish experienced operators.
Step 7: Develop Reliability Thinking
Reliability engineering involves more than technical execution.
Professionals should learn:
- Risk assessment
- Resilience design
- Service measurement
- Performance optimization
- Failure analysis
This mindset supports long-term operational success.
Step 8: Gain Real-World Experience
Practical experience remains essential.
Seek opportunities to:
- Manage production systems
- Participate in on-call rotations
- Troubleshoot incidents
- Automate workflows
- Improve service reliability
Hands-on experience accelerates professional growth.
Step 9: Strengthen Communication Skills
Operations experts collaborate across multiple teams.
Develop abilities in:
- Technical writing
- Incident communication
- Stakeholder management
- Cross-functional collaboration
- Knowledge sharing
Strong communication improves both technical and organizational effectiveness.
Step 10: Commit to Continuous Learning
Technology evolves rapidly.
Successful professionals continuously expand their knowledge through experimentation, training, community engagement, and practical projects.
Lifelong learning remains a defining characteristic of top operations experts.
FAQ Section
What does SRE stand for?
SRE stands for Site Reliability Engineering, a discipline that combines software engineering and IT operations to improve system reliability, scalability, and efficiency.
Why are SRE skills important for IT professionals?
SRE skills help professionals manage complex systems, reduce downtime, automate operations, improve performance, and support business growth through reliable technology services.
Is SRE different from DevOps?
Yes. DevOps focuses on collaboration and delivery practices, while SRE applies engineering principles to achieve reliability goals. However, both disciplines complement each other.
Do I need programming skills for SRE?
Yes. Programming helps automate operational tasks, manage infrastructure, improve monitoring, and create tools that enhance reliability.
Which industries use SRE practices?
Many industries use SRE practices, including finance, healthcare, telecommunications, e-commerce, cloud services, media, and software companies.
What are the most important SRE skills?
Key skills include automation, monitoring, observability, cloud computing, incident management, Linux administration, networking, and reliability engineering.
Is SRE a good career path?
Yes. Organizations increasingly seek professionals who can manage reliability, scalability, and operational efficiency, making SRE a highly valuable career path.
What is observability in SRE?
Observability enables teams to understand system behavior using metrics, logs, traces, and telemetry data for faster troubleshooting and performance analysis.
How does automation help operations teams?
Automation reduces manual effort, improves consistency, minimizes human error, and enables teams to manage large-scale environments efficiently.
Can beginners learn SRE?
Yes. Beginners can start with Linux, networking, cloud fundamentals, scripting, and monitoring concepts before progressing to advanced reliability engineering practices.
Final Summary
SRE skills have become essential for modern IT professionals because organizations depend on reliable digital services to achieve business success. As technology environments grow more complex, companies need engineers who can balance innovation with stability while maintaining excellent customer experiences.
Reliability engineering provides the frameworks, tools, and practices necessary to manage distributed systems effectively. Through monitoring, observability, automation, incident management, and capacity planning, SRE professionals help organizations reduce downtime, improve performance, and strengthen operational resilience.
At the same time, operational excellence requires more than technology. Successful organizations combine powerful platforms with collaborative cultures that emphasize shared ownership, continuous improvement, transparency, and learning. This combination enables teams to achieve sustainable reliability at scale.
For professionals seeking long-term career growth, developing SRE skills offers significant opportunities. By building expertise in cloud computing, automation, observability, reliability engineering, and operational practices, individuals can become valuable contributors to modern technology organizations.
Ultimately, SRE is not simply a job role. It represents a mindset focused on creating dependable systems, improving customer experiences, and enabling organizations to innovate confidently while maintaining operational excellence.