Introduction
Modern businesses depend on reliable digital services. Whether it is an e-commerce platform, banking application, streaming service, or cloud-native product, users expect systems to remain available, fast, and secure at all times. As organizations scale their infrastructure and applications, maintaining reliability becomes increasingly challenging. This is where Site Reliability Engineering (SRE) plays a critical role.
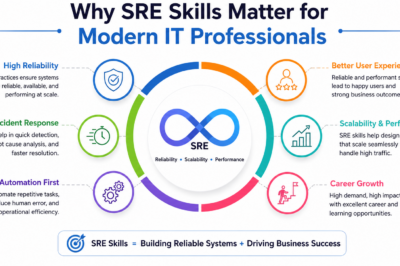
Site Reliability Engineering combines software engineering principles with IT operations practices to build and maintain highly reliable systems. Instead of relying solely on manual operational activities, SRE teams use automation, monitoring, observability, incident management, and performance optimization to ensure services operate efficiently. As a result, organizations can improve uptime, reduce operational risks, and deliver better user experiences.
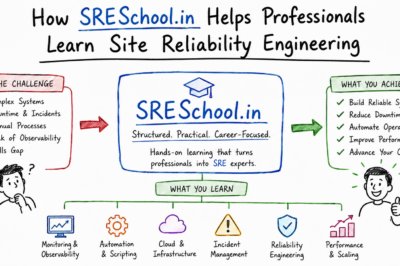
Professionals who want to learn practical Site Reliability Engineering skills can explore programs offered by Sreschool. The platform focuses on real-world operational practices, automation strategies, reliability principles, and modern infrastructure management techniques that help engineers build successful careers in operations and reliability engineering.
This roadmap explains the knowledge, skills, tools, and practical experiences working engineers need to become successful Site Reliability Engineers. Additionally, it covers operational concepts, implementation strategies, common mistakes, real-world use cases, and career growth opportunities.
Understanding Site Reliability Engineering
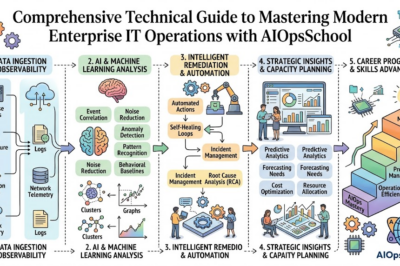
Site Reliability Engineering is a discipline that applies software engineering approaches to operations problems. Traditional operations teams often perform repetitive manual tasks such as deployments, monitoring, troubleshooting, and capacity management. However, SRE teams automate these activities and create scalable systems that require minimal manual intervention.
The primary goal of SRE is to ensure reliability while maintaining development velocity. Organizations need to release features quickly, yet they must also maintain service stability. Therefore, SRE acts as a bridge between development teams and operations teams. By introducing reliability metrics, automation frameworks, observability practices, and incident response procedures, SRE teams help organizations achieve both innovation and stability.
An SRE engineer works with infrastructure, applications, monitoring platforms, automation tools, cloud services, security controls, and operational processes. Consequently, the role demands a broad understanding of software systems and operational excellence.
Why Site Reliability Engineering Matters
Digital transformation has increased system complexity significantly. Modern applications run across containers, microservices, cloud environments, APIs, databases, and distributed networks. Because of this complexity, failures can occur at multiple levels.
Organizations adopt SRE practices because they provide measurable improvements in service quality. Reliable systems improve customer trust, reduce revenue losses caused by downtime, and strengthen operational efficiency. Furthermore, automated operations reduce human errors and allow engineers to focus on innovation instead of repetitive tasks.
Businesses also benefit from improved incident management, better resource utilization, stronger observability, and predictable service performance. Therefore, SRE has become one of the most valuable disciplines in modern technology organizations.
Core Responsibilities of a Site Reliability Engineer
Site Reliability Engineers perform multiple responsibilities that contribute to service stability and operational excellence.
These responsibilities include:
- Designing highly available systems
- Automating operational tasks
- Monitoring service performance
- Managing incidents and outages
- Improving system reliability
- Implementing observability solutions
- Optimizing infrastructure utilization
- Creating operational runbooks
- Supporting deployment processes
- Conducting post-incident reviews
Because reliability impacts every aspect of digital services, SRE professionals collaborate closely with software developers, security engineers, cloud architects, and business stakeholders.
Key Operational Concepts You Must Know
Understanding operational concepts forms the foundation of every successful Site Reliability Engineering career. These concepts help engineers measure reliability, identify risks, and continuously improve service quality.
Service Level Indicators (SLIs)
SLIs are metrics that measure service performance from a user perspective. Examples include request latency, error rates, system availability, and transaction success rates. These indicators help teams understand whether users are receiving acceptable service quality.
Without SLIs, organizations struggle to evaluate service health objectively. Therefore, SRE teams use these metrics to track operational performance continuously.
Service Level Objectives (SLOs)
SLOs define target reliability levels based on business requirements. For example, a service may require 99.9% availability. These objectives create measurable goals for engineering teams and establish expectations across the organization.
Effective SLOs balance reliability requirements with development speed. As a result, teams avoid overengineering while maintaining acceptable service quality.
Error Budgets
Error budgets define acceptable failure levels within a service. Instead of aiming for unrealistic perfection, organizations allow limited failure within agreed thresholds. This approach encourages innovation while protecting reliability.
When error budgets are exhausted, teams prioritize stability improvements before introducing additional changes. Consequently, organizations achieve a healthier balance between feature delivery and operational reliability.
Observability
Observability enables engineers to understand system behavior through metrics, logs, traces, and events. Unlike traditional monitoring, observability helps teams investigate unknown problems efficiently.
Modern observability platforms provide visibility into application performance, infrastructure health, network behavior, and user experiences. Therefore, observability has become a critical capability for SRE teams.
Incident Management
Incident management focuses on identifying, responding to, and resolving operational disruptions. Strong incident management processes minimize downtime and improve organizational resilience.
Teams use escalation procedures, communication protocols, response playbooks, and post-incident reviews to manage incidents effectively. As systems become more complex, structured incident management becomes increasingly important.
Platform Implementation vs. Culture — What’s the Real Difference?
Many organizations mistakenly believe Site Reliability Engineering is only about tools and platforms. However, successful SRE adoption requires both technical implementation and cultural transformation.
Platform Implementation
Platform implementation focuses on building technical capabilities that support reliability. These capabilities include monitoring systems, automation frameworks, deployment pipelines, cloud infrastructure, observability platforms, and incident management solutions.
Engineers implement these technologies to reduce operational overhead and improve system stability. Additionally, platform investments help organizations scale efficiently while maintaining reliability standards.
Technical implementation delivers measurable operational improvements. However, technology alone cannot solve reliability challenges completely.
Operational Culture
Operational culture defines how teams think about reliability, collaboration, accountability, and continuous improvement. Strong SRE cultures encourage shared ownership between development and operations teams.
Instead of assigning reliability responsibilities to a single group, organizations distribute ownership across engineering teams. Consequently, developers become more accountable for production systems while operations teams contribute automation and reliability expertise.
A healthy operational culture also promotes learning from failures. Rather than assigning blame, teams conduct post-incident reviews that focus on systemic improvements. This mindset encourages innovation and long-term reliability growth.
The Real Difference
Platform implementation provides technical capabilities. Culture determines how effectively those capabilities are used.
An organization may invest heavily in monitoring and automation tools yet continue experiencing operational failures if teams lack collaboration and accountability. Conversely, strong culture without technical capabilities may struggle to scale effectively.
Therefore, successful SRE programs combine modern platforms with reliability-focused organizational culture.
Real-World Use Cases of Modern Operations
Modern operations practices support a wide range of business-critical scenarios across industries.
E-Commerce Platforms
Online retailers depend on reliable applications to process customer transactions. Even a few minutes of downtime can result in significant revenue losses.
SRE teams monitor application performance, automate scaling policies, optimize databases, and manage infrastructure reliability. Consequently, customers enjoy consistent shopping experiences during normal operations and high-traffic events.
Financial Services
Banks and financial institutions require extremely reliable systems because service interruptions can impact transactions, compliance requirements, and customer trust.
Operations teams implement redundancy strategies, real-time monitoring, incident response frameworks, and disaster recovery procedures. These capabilities help organizations maintain business continuity and regulatory compliance.
Streaming Services
Media platforms must support millions of users accessing content simultaneously. Traffic patterns change rapidly, especially during major events.
SRE teams manage infrastructure scaling, monitor application latency, optimize content delivery systems, and maintain service availability. As a result, users experience uninterrupted content consumption.
Software-as-a-Service Platforms
SaaS providers deliver services through cloud-based applications. Service reliability directly affects customer satisfaction and retention.
Operations engineers ensure infrastructure stability, automate deployments, monitor user experiences, and optimize application performance. Therefore, SaaS businesses can scale effectively while maintaining customer trust.
Healthcare Systems
Healthcare applications support critical patient services and medical operations. Reliability failures can impact patient care and operational efficiency.
Modern operations teams implement high-availability architectures, security controls, observability solutions, and incident management practices that support continuous healthcare service delivery.
Technical Skills Required for SRE Engineers
Working engineers who want to transition into SRE roles should develop expertise across several technical domains.
| Skill Area | Importance |
|---|---|
| Linux Administration | Infrastructure management |
| Networking | Connectivity and troubleshooting |
| Cloud Platforms | Modern infrastructure operations |
| Programming | Automation development |
| Monitoring | System visibility |
| Containers | Application deployment |
| Kubernetes | Container orchestration |
| CI/CD | Deployment automation |
| Security | Risk reduction |
| Databases | Data platform reliability |
A strong foundation across these areas significantly improves operational effectiveness and career growth opportunities.
Learning Linux and System Administration
Linux remains one of the most important technologies in Site Reliability Engineering. Most cloud environments, container platforms, and enterprise applications rely heavily on Linux systems.
Engineers should understand process management, system services, file systems, permissions, package management, performance monitoring, and troubleshooting techniques. Additionally, they should become comfortable using command-line tools for daily operational activities.
Practical Linux experience improves troubleshooting capabilities and helps engineers diagnose production issues efficiently.
Networking Fundamentals for Reliability Engineers
Reliable systems depend on strong networking knowledge. Engineers must understand how services communicate across distributed environments.
Important networking topics include:
- TCP/IP fundamentals
- DNS resolution
- HTTP and HTTPS protocols
- Load balancing
- Firewalls
- VPN technologies
- Network routing
- Reverse proxies
- CDN architecture
- Traffic analysis
Strong networking skills enable engineers to identify connectivity problems and optimize application performance effectively.
Cloud Computing Knowledge
Most modern organizations operate workloads in cloud environments. Therefore, cloud expertise has become essential for Site Reliability Engineers.
Engineers should understand compute services, storage solutions, networking configurations, identity management, infrastructure automation, and cloud security controls.
Additionally, they should learn how cloud architectures support scalability, resilience, and operational efficiency. Practical cloud experience helps engineers design reliable systems that adapt to changing business requirements.
Programming and Automation Skills
Automation represents a core principle of Site Reliability Engineering. Consequently, engineers should develop programming skills that support operational automation.
Recommended languages include:
- Python
- Go
- Bash
- JavaScript
- PowerShell
Engineers use these languages to automate deployments, manage infrastructure, analyze operational data, build internal tools, and reduce repetitive manual work.
The more effectively engineers automate operations, the more time they can dedicate to reliability improvements and innovation.
Monitoring and Observability Expertise
Monitoring provides visibility into service health, while observability helps teams understand complex system behavior.
Engineers should learn how to collect, analyze, and interpret:
- Metrics
- Logs
- Traces
- Events
- Performance indicators
- Capacity data
Observability skills help engineers identify operational risks before they affect customers. Furthermore, strong visibility improves incident response speed and troubleshooting efficiency.
Containers and Kubernetes
Containerization has transformed modern infrastructure management. Kubernetes has become the standard platform for container orchestration.
Engineers should understand:
- Container architecture
- Docker fundamentals
- Kubernetes deployments
- Service discovery
- Scaling policies
- Resource management
- Networking models
- Security practices
Container expertise allows organizations to deploy applications consistently across multiple environments while maintaining operational flexibility.
Common Mistakes in Operations Engineering
Many engineers encounter challenges during their operational journey. Understanding common mistakes helps avoid costly reliability failures.
Over-Reliance on Manual Processes
Manual operational activities increase the likelihood of human errors. Repetitive tasks consume valuable engineering time and introduce inconsistency.
Automation should replace repetitive activities whenever possible. This approach improves reliability and operational efficiency.
Poor Monitoring Strategies
Some teams collect excessive data without defining meaningful metrics. Others monitor only infrastructure while ignoring application behavior.
Effective monitoring focuses on business-impacting metrics and user experiences rather than collecting data for its own sake.
Ignoring Documentation
Lack of documentation creates operational risks during incidents. Engineers may struggle to understand procedures, configurations, or recovery steps.
Maintaining clear operational documentation improves consistency and accelerates incident resolution.
Weak Incident Reviews
Organizations sometimes treat incidents as isolated events instead of learning opportunities.
Post-incident reviews should identify systemic improvements that reduce future risks. Continuous learning strengthens operational maturity.
Neglecting Capacity Planning
Infrastructure limitations often cause performance degradation during traffic growth.
Regular capacity analysis helps organizations prepare for future demands and maintain service reliability.
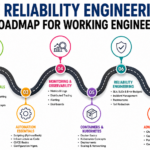
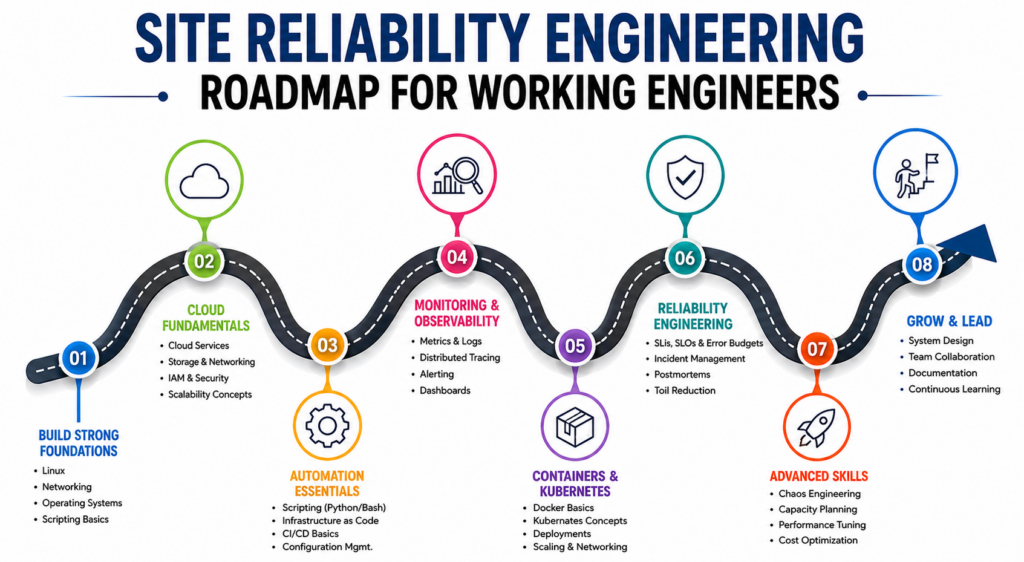
How to Become an Operations Expert — Career Roadmap
A structured roadmap helps working engineers build expertise progressively and transition into advanced operational roles.
Stage 1: Build Technical Foundations
Focus on Linux administration, networking, operating systems, and scripting fundamentals. These skills provide the technical foundation required for operational work.
Spend time troubleshooting systems, understanding infrastructure components, and learning how applications interact with underlying platforms.
Stage 2: Learn Cloud Technologies
Develop expertise in cloud services, virtual infrastructure, storage systems, and networking architectures.
Hands-on cloud projects help engineers understand scalability, resilience, and operational automation principles.
Stage 3: Master Automation
Automation differentiates modern operations professionals from traditional administrators.
Create scripts, automate workflows, manage infrastructure as code, and reduce manual operational activities wherever possible.
Stage 4: Develop Observability Skills
Learn monitoring, logging, tracing, alerting, and performance analysis techniques.
Strong observability capabilities enable engineers to identify operational risks proactively and improve system reliability continuously.
Stage 5: Gain Production Experience
Real-world production experience provides invaluable learning opportunities.
Participate in deployments, incident response activities, troubleshooting sessions, and operational reviews. Practical exposure accelerates professional growth significantly.
Stage 6: Learn Reliability Engineering Principles
Study SLIs, SLOs, error budgets, incident management, resilience engineering, and service reliability strategies.
These concepts help engineers transition from infrastructure management toward reliability-focused operations.
Stage 7: Lead Operational Improvements
As expertise grows, engineers should contribute to architecture reviews, automation initiatives, operational standards, and reliability programs.
Leadership experience strengthens career advancement opportunities and increases organizational impact.
Recommended Career Progression
- System Administrator
- Operations Engineer
- Cloud Engineer
- DevOps Engineer
- Site Reliability Engineer
- Senior SRE
- Reliability Architect
- Platform Engineering Lead
- Head of Reliability Engineering
Each stage builds additional technical depth, operational experience, and leadership capabilities.
FAQ Section
What is Site Reliability Engineering?
Site Reliability Engineering is a discipline that combines software engineering and operations practices to improve system reliability, scalability, and performance.
Is programming necessary for SRE?
Yes. Programming helps automate operational tasks, build internal tools, and improve infrastructure efficiency.
Which operating system should I learn first?
Linux is the most important operating system for Site Reliability Engineering because most cloud and container environments rely on it.
Is cloud knowledge mandatory for modern SRE roles?
Yes. Most organizations operate workloads in cloud environments, making cloud expertise essential for modern reliability engineering.
How long does it take to become an SRE?
The timeline varies depending on existing experience, learning pace, and practical exposure. Consistent hands-on practice accelerates progress significantly.
Which programming language is best for SRE?
Python and Go are among the most commonly used languages because they support automation, infrastructure management, and tooling development effectively.
What is the difference between DevOps and SRE?
DevOps focuses on collaboration and delivery practices, while SRE applies engineering principles to achieve measurable reliability objectives.
Do SRE engineers handle incidents?
Yes. Incident response is a major responsibility. SRE teams investigate, mitigate, resolve, and learn from operational disruptions.
Is Kubernetes important for SRE careers?
Yes. Kubernetes has become a widely adopted platform for managing containerized applications and modern infrastructure.
What makes a successful Site Reliability Engineer?
Successful SRE engineers combine technical expertise, automation skills, operational discipline, problem-solving abilities, and continuous learning habits.
Final Summary
Site Reliability Engineering has become one of the most important disciplines in modern technology organizations. As digital systems grow more complex, businesses need professionals who can balance innovation with reliability. SRE achieves this balance by combining software engineering practices, automation strategies, observability techniques, and operational excellence principles.
Working engineers who want to enter this field should focus on Linux administration, networking, cloud computing, automation, monitoring, containers, Kubernetes, and reliability engineering fundamentals. Additionally, they should gain practical production experience and develop strong troubleshooting capabilities.
Success in Site Reliability Engineering requires more than technical knowledge. Engineers must also embrace continuous improvement, collaborative culture, operational ownership, and learning from failures. By following a structured roadmap and consistently building practical skills, professionals can grow into highly valuable reliability experts capable of designing and operating resilient systems at scale.