Introduction
Technology systems have become the foundation of modern businesses. From online shopping platforms and banking applications to healthcare systems and media streaming services, organizations depend on reliable digital services every day. However, building software is only one part of the challenge. Keeping that software available, secure, scalable, and efficient is equally important. This is where Site Reliability Engineering (SRE) plays a critical role.
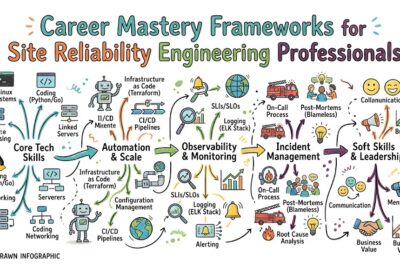
Site Reliability Engineering is a discipline that combines software engineering principles with IT operations practices. The goal is simple: create reliable systems that can support business growth while maintaining excellent user experiences. SRE professionals focus on automation, monitoring, performance optimization, incident management, capacity planning, and continuous improvement.
As organizations increasingly adopt cloud technologies and distributed architectures, the demand for skilled SRE professionals continues to grow. Many engineers, system administrators, DevOps practitioners, and IT professionals are now looking for structured ways to build expertise in this field.
One platform helping professionals develop these skills is Sreschool. Through practical learning approaches, industry-focused training, and hands-on exposure to modern operational practices, Sreschool helps learners understand both the technical and strategic aspects of Site Reliability Engineering.
This guide explores how professionals can learn Site Reliability Engineering effectively, the essential operational concepts involved, common industry challenges, and how structured learning can support long-term career growth.
Understanding Site Reliability Engineering
Before exploring how professionals learn SRE, it is important to understand what the discipline actually involves.
Site Reliability Engineering focuses on ensuring that systems remain dependable under real-world conditions. Instead of relying solely on manual operational processes, SRE introduces engineering solutions that automate repetitive work and reduce operational risk.
Traditional operations teams often spend significant time responding to incidents, managing infrastructure, and handling routine maintenance tasks. SRE approaches these responsibilities differently by emphasizing automation and software-driven operations.
Key objectives of Site Reliability Engineering include:
- Improving service availability
- Reducing operational overhead
- Enhancing system performance
- Increasing deployment confidence
- Preventing recurring incidents
- Supporting business scalability
- Improving customer experience
Rather than treating reliability as an afterthought, SRE integrates reliability goals directly into system design and operational processes.
This mindset helps organizations create systems that are resilient, efficient, and easier to manage over time.
Why Learning SRE Has Become Important
Modern technology environments are far more complex than traditional IT infrastructures.
Organizations now manage:
- Cloud-native applications
- Containerized workloads
- Distributed services
- Multi-region deployments
- Large-scale databases
- Continuous delivery pipelines
- Complex monitoring ecosystems
As complexity increases, the risk of service disruptions also grows.
Companies therefore need professionals who understand both software engineering and operational excellence. SRE bridges this gap by teaching engineers how to think beyond code and consider system reliability as a core responsibility.
Learning SRE provides several advantages:
| Benefit | Impact |
|---|---|
| Better Technical Skills | Improves understanding of modern infrastructure |
| Career Growth | Opens opportunities in high-demand roles |
| Problem-Solving Ability | Develops systematic troubleshooting approaches |
| Automation Expertise | Reduces manual operational work |
| Cloud Readiness | Supports modern cloud environments |
| Reliability Focus | Enhances service quality and customer satisfaction |
Because of these benefits, many professionals are actively investing in structured SRE education.
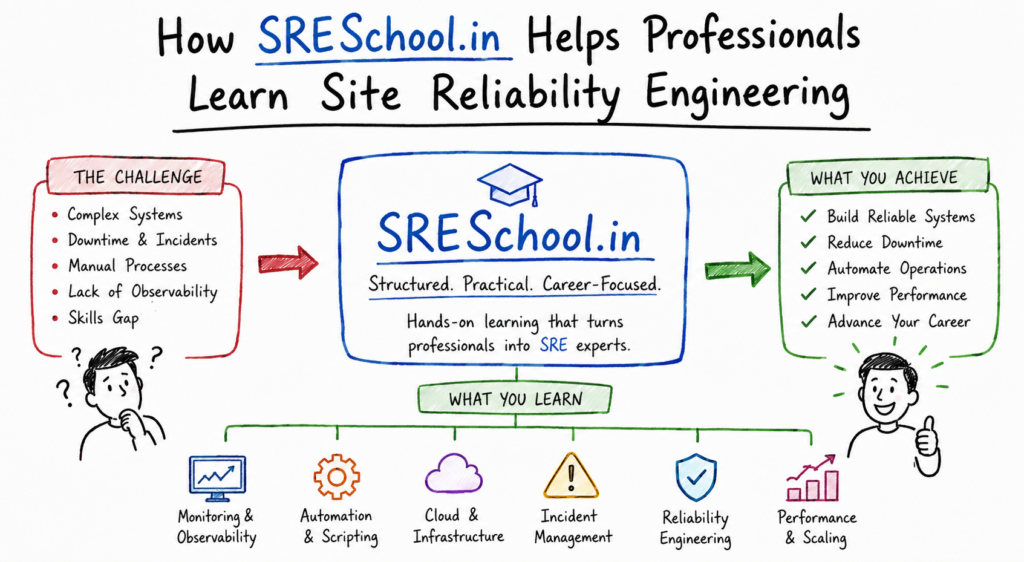
How SRESchool.in Helps Professionals Learn Site Reliability Engineering
Learning Site Reliability Engineering requires more than theoretical knowledge. Professionals must understand how systems behave under real operational conditions.
Sreschool helps learners bridge this gap through practical and structured learning experiences.
Focus on Industry-Relevant Concepts
Many learners struggle because operational engineering involves numerous interconnected topics.
Sreschool helps organize these concepts into structured learning paths, making it easier for professionals to understand how different technologies work together.
Learners gain exposure to areas such as:
- Infrastructure management
- Reliability engineering
- Observability
- Cloud platforms
- Automation workflows
- Incident response
- Service management
This structured progression reduces confusion and accelerates learning.
Practical Learning Approach
Theory alone rarely prepares engineers for production environments.
Professionals need practical understanding of:
- System failures
- Service recovery
- Monitoring strategies
- Performance bottlenecks
- Scaling challenges
A hands-on learning approach helps learners build confidence in solving operational problems.
Practical exercises allow professionals to apply concepts instead of simply memorizing definitions.
Exposure to Real Operational Scenarios
One major challenge in SRE education is understanding real-world operational behavior.
Systems rarely fail in predictable ways.
Engineers must learn how to:
- Analyze incidents
- Investigate root causes
- Review system metrics
- Improve reliability
- Prevent recurring issues
Learning through realistic operational scenarios helps professionals develop stronger decision-making skills.
Supporting Career Transition
Many learners come from different backgrounds.
Common transitions include:
- System Administrator to SRE
- DevOps Engineer to Reliability Engineer
- Software Developer to Platform Engineer
- Cloud Engineer to SRE Specialist
- Operations Engineer to Infrastructure Architect
Sreschool helps learners understand the skills required for these transitions and build relevant expertise.
Building Long-Term Operational Thinking
Site Reliability Engineering is not just a collection of tools.
It is a way of thinking.
Professionals must learn how to:
- Measure reliability
- Balance innovation and stability
- Prioritize engineering effort
- Manage operational risk
- Continuously improve systems
Developing this mindset is critical for long-term success.
Key Operational Concepts You Must Know
Every aspiring SRE professional should understand several foundational operational concepts.
These concepts form the backbone of reliable system design and management.
Reliability
Reliability measures a system’s ability to function correctly over time.
Reliable systems consistently deliver expected outcomes even during high demand or unexpected conditions.
Reliability requires:
- Fault tolerance
- Monitoring
- Redundancy
- Recovery planning
Without reliability, business services become unpredictable.
Availability
Availability refers to how often a service remains accessible to users.
High availability minimizes downtime and ensures uninterrupted access.
Strategies include:
- Load balancing
- Multi-region deployment
- Automated failover
- Redundant infrastructure
Availability directly impacts customer satisfaction.
Scalability
Scalability determines how effectively systems handle growth.
As user demand increases, systems must continue performing efficiently.
Scalable architectures support:
- Traffic growth
- Data expansion
- Business growth
- Global operations
Scalability prevents performance degradation during peak usage.
Monitoring
Monitoring provides visibility into system behavior.
Without monitoring, engineers operate blindly.
Monitoring helps teams track:
- Resource utilization
- Application performance
- Error rates
- User activity
- Infrastructure health
Effective monitoring enables faster problem detection.
Observability
Observability goes beyond monitoring.
It helps engineers understand why systems behave in certain ways.
Observability relies on:
- Metrics
- Logs
- Traces
Together, these data sources provide deeper operational insights.
Incident Management
Incidents are inevitable.
The goal is not eliminating every failure but responding effectively when failures occur.
Strong incident management includes:
- Rapid detection
- Clear communication
- Root cause analysis
- Post-incident reviews
Organizations with mature incident processes recover faster.
Automation
Automation is one of the most important SRE principles.
Manual processes often introduce delays and human errors.
Automation improves:
- Consistency
- Efficiency
- Reliability
- Deployment speed
Engineers should automate repetitive tasks whenever possible.
Capacity Planning
Capacity planning ensures systems can support future demand.
Poor planning often leads to:
- Resource shortages
- Performance issues
- Unexpected outages
Reliable forecasting helps organizations prepare for growth.
Platform Implementation vs. Culture — What’s the Real Difference?
Many organizations focus heavily on technology while overlooking cultural factors.
However, successful operations require both platform implementation and organizational culture.
Understanding the distinction is essential.
What Is Platform Implementation?
Platform implementation focuses on technical capabilities.
Examples include:
- Cloud infrastructure
- Monitoring systems
- Deployment pipelines
- Automation frameworks
- Security controls
These tools provide the operational foundation required for modern systems.
Technical platforms help teams work efficiently and consistently.
What Is Operational Culture?
Culture focuses on how people collaborate and make decisions.
Strong operational cultures encourage:
- Shared responsibility
- Continuous learning
- Transparency
- Accountability
- Improvement-focused thinking
Culture influences how teams respond to challenges.
Why Technology Alone Is Not Enough
Many organizations invest heavily in tools but still experience operational problems.
Common issues include:
- Poor communication
- Lack of ownership
- Slow incident response
- Knowledge silos
- Blame-oriented environments
Even advanced platforms cannot compensate for weak collaboration.
Why Culture Matters
Healthy operational cultures encourage teams to learn from failures.
Instead of assigning blame, teams focus on:
- Understanding causes
- Improving processes
- Sharing knowledge
- Preventing recurrence
This mindset supports continuous reliability improvements.
Achieving Balance
The strongest organizations balance technical excellence with operational maturity.
They invest in:
- Modern platforms
- Skilled engineers
- Process improvement
- Team collaboration
This balanced approach creates sustainable operational success.
Real-World Use Cases of Modern Operations
Operations engineering affects nearly every industry.
Understanding practical use cases helps professionals connect theory with real business outcomes.
E-Commerce Platforms
Online retailers depend on reliable systems.
Operational teams ensure:
- Checkout functionality
- Inventory synchronization
- Payment processing
- Website availability
Even short disruptions can impact revenue significantly.
Financial Services
Banks and financial institutions require extremely reliable systems.
Operations professionals manage:
- Transaction processing
- Fraud detection systems
- Customer portals
- Payment infrastructure
Reliability is critical because downtime can affect customer trust.
Healthcare Systems
Healthcare organizations rely on technology for patient care.
Operational teams support:
- Medical records systems
- Appointment platforms
- Diagnostic applications
- Communication systems
Reliable healthcare services directly impact patient outcomes.
Media Streaming Services
Streaming platforms handle enormous traffic volumes.
Operations teams focus on:
- Content delivery
- Performance optimization
- Scalability management
- Regional availability
Users expect uninterrupted viewing experiences.
Software-as-a-Service Platforms
SaaS providers deliver applications through cloud environments.
Operations engineers ensure:
- Service uptime
- Data protection
- Performance stability
- Infrastructure efficiency
Reliable SaaS services strengthen customer retention.
Telecommunications
Telecommunication providers manage large-scale infrastructure.
Operational responsibilities include:
- Network reliability
- Service continuity
- Traffic optimization
- Capacity management
Strong operations support consistent connectivity.
Manufacturing and Industrial Systems
Industrial operations increasingly rely on digital systems.
Reliability engineers help maintain:
- Production systems
- Monitoring platforms
- Supply chain applications
- Operational analytics
Technology disruptions can impact physical production processes.
Common Mistakes in Operations Engineering
Many operational failures result from preventable mistakes.
Recognizing these issues helps professionals avoid common pitfalls.
Overreliance on Manual Processes
Manual tasks increase operational risk.
Problems include:
- Human error
- Delayed execution
- Inconsistent outcomes
Automation significantly reduces these challenges.
Ignoring Monitoring Data
Collecting metrics is not enough.
Teams must actively review and act on operational insights.
Unused monitoring systems provide little value.
Poor Documentation
Knowledge trapped in individual team members creates risk.
Strong documentation improves:
- Onboarding
- Incident response
- Operational consistency
Documentation should remain current and accessible.
Reactive Operations
Some teams focus only on fixing problems after they occur.
A proactive approach is far more effective.
Proactive operations involve:
- Trend analysis
- Capacity forecasting
- Reliability improvements
- Preventive maintenance
Prevention often costs less than recovery.
Weak Incident Reviews
Incident reviews provide valuable learning opportunities.
Organizations should avoid:
- Blame-focused discussions
- Superficial analysis
- Incomplete investigations
Effective reviews drive long-term improvements.
Lack of Reliability Metrics
Without measurable goals, reliability becomes difficult to manage.
Teams should define clear objectives and monitor progress consistently.
Data-driven decision making improves operational effectiveness.
Tool-Centric Thinking
Tools are valuable, but they are not complete solutions.
Successful operations require:
- Skilled people
- Effective processes
- Clear objectives
Technology should support strategy rather than replace it.
How to Become an Operations Expert — Career Roadmap
Many professionals wonder how to build a successful operations career.
The journey typically involves several stages.
Stage 1: Build Strong Technical Foundations
Start by understanding core technical concepts.
Focus on:
- Operating systems
- Networking
- Linux administration
- Cloud fundamentals
- Basic programming
These skills create a strong foundation.
Stage 2: Learn Automation
Automation is a critical operational capability.
Develop skills in:
- Scripting
- Infrastructure automation
- Configuration management
- Workflow automation
Automation improves efficiency and scalability.
Stage 3: Master Monitoring and Observability
Visibility is essential.
Learn how to work with:
- Metrics
- Logs
- Traces
- Alerting systems
Observability skills help engineers diagnose complex issues.
Stage 4: Understand Cloud Platforms
Modern operations heavily depend on cloud environments.
Study concepts such as:
- Virtual infrastructure
- Container orchestration
- Cloud networking
- Managed services
Cloud expertise significantly increases career opportunities.
Stage 5: Develop Incident Response Skills
Real-world operational experience is invaluable.
Learn how to:
- Troubleshoot failures
- Coordinate responses
- Communicate effectively
- Analyze root causes
These skills improve confidence during high-pressure situations.
Stage 6: Learn Reliability Engineering Principles
Advanced professionals focus on:
- Service level objectives
- Reliability metrics
- Capacity planning
- Performance engineering
These concepts distinguish experienced engineers from beginners.
Stage 7: Build Leadership Capabilities
Senior operations professionals often guide teams.
Important leadership skills include:
- Mentoring
- Communication
- Decision making
- Strategic planning
Technical expertise combined with leadership creates long-term career growth.
Recommended Learning Path by Role
| Current Role | Recommended Focus |
|---|---|
| System Administrator | Automation, cloud infrastructure |
| Software Developer | Reliability engineering, observability |
| DevOps Engineer | Advanced SRE practices |
| Cloud Engineer | Reliability metrics and operations |
| Network Engineer | Monitoring and distributed systems |
| IT Support Professional | Linux, scripting, infrastructure fundamentals |
Following a structured roadmap helps professionals progress more efficiently.
FAQ Section
What is Site Reliability Engineering?
Site Reliability Engineering is a discipline that applies software engineering practices to infrastructure and operations to improve system reliability, scalability, and performance.
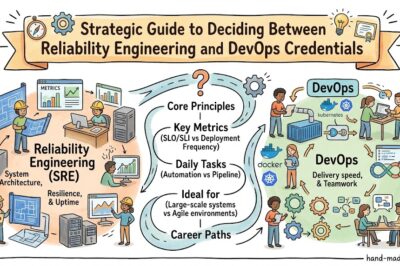
Is SRE different from DevOps?
Yes. DevOps focuses on collaboration between development and operations, while SRE applies engineering methods to achieve measurable reliability goals.
Do I need programming skills to learn SRE?
Programming skills are highly beneficial because automation is a fundamental part of modern reliability engineering.
Can beginners learn Site Reliability Engineering?
Yes. Beginners can start with Linux, networking, cloud fundamentals, and automation before moving into advanced reliability concepts.
Why is observability important?
Observability helps engineers understand system behavior, diagnose problems, and improve operational decision making.
Is cloud knowledge required for SRE?
Most modern SRE roles involve cloud environments, making cloud knowledge highly valuable.
What industries hire SRE professionals?
Industries include technology, finance, healthcare, telecommunications, e-commerce, manufacturing, and media services.
How long does it take to become proficient in SRE?
The timeline varies based on prior experience, learning commitment, and practical exposure to operational environments.
What are the most important SRE skills?
Key skills include automation, monitoring, observability, cloud computing, incident management, networking, and reliability engineering.
How can structured learning help aspiring SRE professionals?
Structured learning provides clear progression, practical exposure, industry-relevant knowledge, and a guided path for skill development.
Final Summary
Site Reliability Engineering has become one of the most valuable disciplines in modern technology environments. As systems grow increasingly complex, organizations need professionals who can maintain reliability while supporting continuous innovation and business growth.
SRE combines software engineering, operations management, automation, monitoring, incident response, and reliability practices into a unified approach for managing modern systems. Rather than relying solely on manual operational processes, SRE encourages engineers to build scalable and automated solutions that improve efficiency and reduce risk.
Professionals who invest in learning SRE gain valuable technical and strategic capabilities. They learn how to build resilient systems, improve service quality, respond effectively to incidents, optimize infrastructure performance, and support large-scale digital operations.
Sreschool helps professionals develop these skills through structured learning, practical exposure, and industry-relevant operational concepts. By focusing on both technical implementation and operational thinking, learners can build a strong foundation for long-term career growth.
Whether someone is a system administrator, developer, cloud engineer, DevOps practitioner, or operations specialist, understanding Site Reliability Engineering can open new opportunities and strengthen their ability to manage modern technology environments successfully.
The path to becoming an operations expert requires continuous learning, hands-on experience, and a commitment to reliability-focused thinking. With the right learning approach and dedication, professionals can build the expertise needed to thrive in today’s increasingly complex operational landscape.