Modern businesses depend on digital systems to deliver services, manage operations, support customers, and drive revenue. Whether it is an e-commerce platform, banking application, healthcare system, SaaS product, or enterprise portal, users expect fast performance, high availability, and uninterrupted access. However, as systems become more complex, maintaining reliability becomes increasingly challenging. Infrastructure failures, software bugs, traffic spikes, security incidents, and configuration errors can quickly impact customer experience and business outcomes.
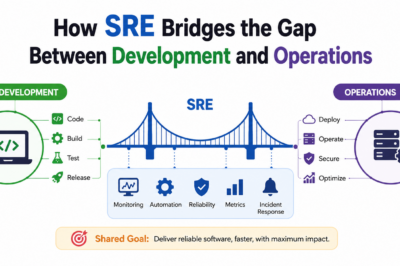
This is where Sreschool and the principles of Site Reliability Engineering (SRE) become highly relevant. Site Reliability Engineering combines software engineering practices with IT operations to build scalable, reliable, and efficient systems. Instead of reacting to outages after they occur, organizations use SRE practices to proactively improve reliability, automate operational work, reduce downtime, and create predictable service performance. As a result, businesses can innovate faster while maintaining the stability that customers expect from modern digital services.
Understanding Site Reliability Engineering and Its Business Value
Site Reliability Engineering is an operational discipline that applies software engineering techniques to infrastructure and operations challenges. Traditional operations teams often spend significant time handling incidents, troubleshooting failures, and performing repetitive tasks. In contrast, SRE focuses on automation, observability, reliability measurement, and continuous improvement.
Organizations increasingly rely on distributed systems, cloud platforms, microservices, APIs, and hybrid environments. These technologies provide flexibility and scalability, yet they also introduce operational complexity. SRE helps businesses manage this complexity by establishing measurable reliability objectives, automating routine work, and creating systems that can recover quickly from failures. Consequently, teams spend less time firefighting and more time improving products and customer experiences.
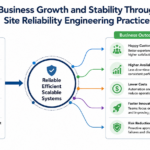
From a business perspective, reliability directly affects revenue, reputation, and customer retention. Customers rarely tolerate slow applications or frequent outages. Even a few minutes of downtime can lead to financial losses and damage customer trust. Therefore, companies that invest in reliability practices gain a competitive advantage while reducing operational risks across their technology ecosystem.
Why Reliability Has Become a Strategic Business Requirement
Reliability is no longer simply a technical metric. It has become a business requirement because customers interact with digital platforms around the clock. Every service interruption affects customer satisfaction, brand perception, and organizational credibility.
Modern businesses also operate in highly competitive markets. Customers can easily switch to alternative providers if they experience repeated performance issues. Therefore, organizations must ensure that applications remain available, responsive, and secure under varying workloads. SRE provides the frameworks and operational practices needed to achieve these goals consistently.
Furthermore, regulatory compliance, data protection requirements, and service-level commitments often demand strict reliability standards. By implementing SRE practices, organizations establish structured processes that support both technical excellence and business accountability.
Key Operational Concepts You Must Know
Understanding the core concepts of Site Reliability Engineering is essential before implementing reliability programs. These concepts form the foundation of modern operations and guide decision-making across engineering and business teams.
Service Level Indicators (SLIs)
Service Level Indicators measure specific aspects of system performance and reliability. These metrics help organizations understand whether services are meeting user expectations. Common SLIs include availability, latency, error rates, throughput, and response times.
Organizations use SLIs to evaluate real-world service quality rather than relying solely on infrastructure metrics. For example, server health may appear normal while users experience slow transactions. SLIs provide visibility into customer-facing performance and help teams focus on outcomes that truly matter. As systems grow more complex, these measurements become increasingly important for maintaining operational excellence and identifying emerging reliability risks.
Service Level Objectives (SLOs)
Service Level Objectives define target reliability levels for services. They establish clear expectations regarding performance and availability. For example, an organization may define an availability objective that requires a service to remain accessible for a specific percentage of time.
SLOs create alignment between business priorities and engineering efforts. Instead of striving for unrealistic perfection, teams establish practical reliability goals that balance innovation with stability. These objectives guide operational decisions, incident response strategies, and infrastructure investments. Moreover, SLOs provide measurable benchmarks that help organizations continuously improve service quality while maintaining business agility.
Error Budgets
Error budgets represent the acceptable amount of unreliability within a defined period. They allow organizations to balance innovation and reliability without compromising customer experience.
When services perform within established reliability objectives, teams can focus on deploying new features and improvements. However, if reliability declines and the error budget is exhausted, engineering teams prioritize stability initiatives. This approach encourages responsible innovation while ensuring operational health. Error budgets also promote healthy collaboration between development and operations teams by creating shared accountability for service performance.
Observability
Observability enables teams to understand system behavior by collecting and analyzing logs, metrics, traces, and events. It provides deep visibility into application performance and infrastructure health.
Modern systems often consist of hundreds of interconnected services. Without observability, identifying root causes during incidents becomes extremely difficult. Through comprehensive monitoring and telemetry collection, teams can quickly detect anomalies, diagnose problems, and restore services. Observability also supports proactive optimization by revealing patterns that indicate potential failures before they impact users.
Automation
Automation is one of the most important principles of Site Reliability Engineering. Repetitive manual processes increase operational costs and introduce human error. Automation eliminates these inefficiencies while improving consistency.
Organizations automate infrastructure provisioning, deployments, incident responses, monitoring activities, and maintenance tasks. As a result, teams can focus on strategic improvements instead of routine operational work. Automation also enhances scalability because systems can handle growing workloads without requiring proportional increases in operational resources.
Why Modern Businesses Cannot Ignore Site Reliability Engineering
Businesses today operate in environments where customers expect seamless digital experiences. Reliability failures can disrupt revenue streams, affect employee productivity, and damage customer trust within minutes.
As organizations adopt cloud-native architectures, microservices, and global delivery models, operational complexity increases significantly. Traditional approaches often struggle to manage these environments efficiently. SRE introduces engineering-driven operational practices that help organizations maintain control over complex systems while supporting rapid growth.
Additionally, business leaders increasingly recognize the relationship between technology reliability and organizational success. Reliable services enable better customer experiences, faster innovation cycles, stronger compliance, and improved operational efficiency. Consequently, SRE has evolved from a specialized practice into a strategic capability that supports long-term business objectives.
Improving Customer Satisfaction
Reliable systems directly contribute to positive customer experiences. Customers expect applications to load quickly, process transactions accurately, and remain available whenever needed.
By implementing SRE principles, organizations reduce downtime, minimize latency issues, and improve overall service quality. Customers experience fewer disruptions, leading to greater satisfaction and loyalty. Over time, these improvements strengthen brand reputation and create sustainable competitive advantages.
Supporting Business Growth
Business growth often leads to increased traffic, larger datasets, and more complex operational requirements. Without proper reliability practices, scaling systems can introduce significant risks.
SRE enables organizations to scale confidently by implementing automation, capacity planning, and performance monitoring strategies. Teams can support growth initiatives without compromising service quality. As a result, businesses expand operations while maintaining stability and operational efficiency.
Reducing Operational Costs
Unexpected outages and manual operational processes create substantial costs. Incident investigations, emergency fixes, and productivity losses consume valuable resources.
SRE reduces these costs by preventing incidents, automating routine tasks, and improving operational efficiency. Teams spend less time reacting to problems and more time delivering value. Consequently, organizations achieve better resource utilization while reducing long-term operational expenses.
Platform Implementation vs. Culture — What’s the Real Difference?
Many organizations mistakenly believe that implementing monitoring tools and automation platforms automatically creates reliability. While technology platforms are important, successful Site Reliability Engineering depends equally on organizational culture.
Understanding Platform Implementation
Platform implementation focuses on technology adoption. Organizations deploy monitoring systems, logging platforms, automation frameworks, observability solutions, and incident management tools.
These technologies provide visibility and operational capabilities that support reliability initiatives. Teams can monitor service health, automate deployments, collect telemetry data, and coordinate incident responses more effectively. However, technology alone does not guarantee operational excellence.
Without proper processes, ownership, and collaboration, even the most advanced platforms fail to deliver expected outcomes. Therefore, platform implementation should be viewed as an enabler rather than the final objective.
Understanding Reliability Culture
Reliability culture focuses on people, processes, and shared accountability. Teams prioritize reliability during design, development, testing, deployment, and operational activities.
In a strong reliability culture, engineers proactively identify risks, learn from failures, and continuously improve systems. Incident reviews emphasize learning rather than blame. Cross-functional collaboration becomes standard practice. Reliability metrics influence decision-making across departments.
This cultural transformation creates sustainable improvements because reliability becomes part of everyday operations rather than an isolated initiative.
Comparing Technology and Culture
| Platform Implementation | Reliability Culture |
|---|---|
| Focuses on tools and systems | Focuses on behaviors and practices |
| Provides operational visibility | Creates operational accountability |
| Enables automation | Encourages continuous improvement |
| Supports monitoring | Supports learning from failures |
| Delivers technical capabilities | Delivers organizational resilience |
Organizations achieve the best results when technology investments and cultural development progress together. A balanced approach creates lasting operational excellence.
Real-World Use Cases of Modern Operations
Site Reliability Engineering delivers measurable benefits across multiple industries and operational environments. These real-world applications demonstrate how reliability practices solve critical business challenges.
E-Commerce Platforms
Online retailers experience significant traffic fluctuations during promotional campaigns, seasonal events, and product launches. Performance issues during these periods can result in lost revenue and customer dissatisfaction.
SRE teams implement capacity planning, automated scaling, observability solutions, and performance monitoring systems. These capabilities ensure that applications remain responsive under heavy workloads. Furthermore, proactive reliability management helps businesses maintain seamless shopping experiences during peak demand periods.
Financial Services
Banks, payment processors, and financial technology companies require extremely reliable systems because customers depend on uninterrupted transaction processing.
SRE practices help financial organizations maintain service availability, monitor transaction performance, and detect operational anomalies quickly. Through automation and observability, teams reduce incident response times while ensuring compliance with strict operational standards. Reliability improvements directly support customer trust and business continuity.
Healthcare Systems
Healthcare organizations rely on digital platforms to manage patient records, appointments, diagnostics, and treatment workflows. System failures can significantly affect patient care and operational efficiency.
SRE enables healthcare providers to improve service reliability through proactive monitoring, automated recovery mechanisms, and incident management processes. These practices support continuous availability while reducing risks associated with critical healthcare operations.
Software-as-a-Service Platforms
SaaS providers compete based on service quality, availability, and user experience. Frequent outages can lead to customer churn and revenue losses.
By adopting SRE methodologies, SaaS companies establish reliability objectives, automate operational tasks, and improve observability across their platforms. These improvements enable faster innovation while maintaining stable customer experiences.
Telecommunications Operations
Telecommunication providers manage complex networks that support millions of users. Reliability challenges include network congestion, service disruptions, and infrastructure failures.
SRE practices help operators monitor network health, automate incident responses, and optimize performance continuously. These capabilities improve service quality while supporting large-scale operational environments.
Common Mistakes in Operations Engineering
Many organizations encounter challenges when building reliability programs. Understanding common mistakes helps teams avoid costly setbacks and accelerate operational maturity.
Treating Reliability as an Afterthought
Some organizations focus exclusively on feature development while postponing reliability considerations. This approach often creates technical debt and operational instability.
Reliability should be integrated into every stage of the software lifecycle. Teams must evaluate operational impacts during design, development, testing, and deployment activities. Early investment in reliability reduces future risks and supports sustainable growth.
Overreliance on Manual Processes
Manual operations increase the likelihood of human error while limiting scalability. Repetitive tasks consume valuable engineering resources and slow response times.
Organizations should prioritize automation whenever possible. Automated deployments, monitoring, incident handling, and infrastructure management improve consistency while reducing operational burdens. Automation enables teams to focus on higher-value activities.
Ignoring Observability
Without adequate observability, teams struggle to understand system behavior during incidents. Limited visibility delays troubleshooting efforts and extends service disruptions.
Comprehensive monitoring, logging, tracing, and telemetry collection provide critical operational insights. Organizations should invest in observability capabilities that support rapid diagnosis and proactive optimization.
Poor Incident Management Practices
Some teams lack structured incident response procedures. As a result, communication breakdowns and delayed decision-making can worsen service disruptions.
Effective incident management requires clearly defined roles, communication channels, escalation processes, and post-incident reviews. Structured approaches improve response efficiency and support continuous learning.
Focusing Only on Tools
Organizations sometimes believe purchasing new tools automatically improves reliability. However, technology cannot compensate for weak processes or poor collaboration.
Successful SRE programs combine technology, culture, processes, and leadership support. Teams should view tools as enablers rather than complete solutions.
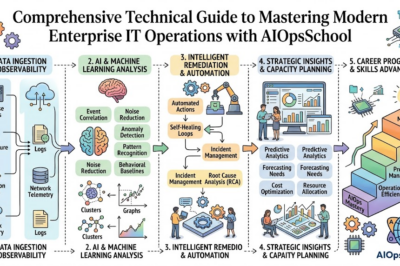
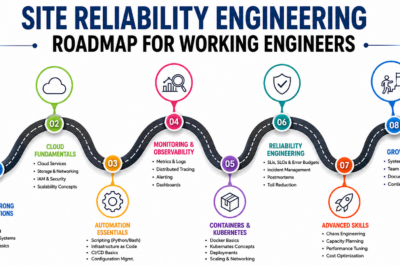
How to Become an Operations Expert — Career Roadmap
Site Reliability Engineering offers excellent career opportunities for professionals interested in reliability, automation, infrastructure, and cloud technologies. Building expertise requires a combination of technical skills, operational experience, and continuous learning.
Step 1: Build Strong Technical Foundations
Start by learning operating systems, networking fundamentals, databases, cloud platforms, and programming concepts. These foundational skills provide essential knowledge for understanding modern infrastructure environments.
Focus on Linux administration, networking protocols, scripting languages, and system troubleshooting techniques. Strong fundamentals make advanced reliability concepts easier to understand and apply.
Step 2: Learn Automation and Scripting
Automation is a core competency for operations professionals. Learn scripting languages such as Python, Bash, or Go to automate repetitive operational tasks.
Develop practical experience with infrastructure automation, configuration management, and deployment pipelines. Automation skills improve efficiency while demonstrating engineering-focused operational thinking.
Step 3: Master Cloud Technologies
Modern organizations increasingly rely on cloud infrastructure. Understanding cloud platforms is essential for reliability engineering careers.
Key learning areas include:
- Cloud architecture fundamentals
- Infrastructure as Code
- Container technologies
- Kubernetes orchestration
- Monitoring and observability
- Security best practices
- Scalability design patterns
These skills prepare professionals for complex operational environments.
Step 4: Develop Reliability Engineering Skills
Learn core SRE concepts including:
- Service Level Indicators
- Service Level Objectives
- Error Budgets
- Incident Management
- Capacity Planning
- Disaster Recovery
- Performance Engineering
- Reliability Metrics
Practical application of these concepts builds operational expertise and industry credibility.
Step 5: Gain Hands-On Experience
Real-world experience accelerates learning significantly. Participate in production support activities, monitoring initiatives, automation projects, and incident response exercises.
Hands-on experience exposes professionals to operational challenges that cannot be fully understood through theoretical study alone. Each operational scenario provides opportunities to strengthen problem-solving capabilities.
Step 6: Pursue Specialized Training
Structured learning programs help professionals develop expertise efficiently. Specialized training provides guidance, practical labs, industry best practices, and exposure to real-world reliability scenarios.
Organizations increasingly seek professionals who can combine software engineering knowledge with operational excellence. Continuous learning remains essential because technologies and operational practices continue evolving.
Career Opportunities in Reliability Engineering
| Role | Primary Focus |
|---|---|
| Site Reliability Engineer | Reliability, automation, scalability |
| DevOps Engineer | CI/CD, automation, infrastructure |
| Platform Engineer | Internal developer platforms |
| Cloud Engineer | Cloud infrastructure management |
| Systems Engineer | Infrastructure operations |
| Observability Engineer | Monitoring and telemetry |
| Production Support Engineer | Incident management |
| Infrastructure Architect | System design and scalability |
FAQ Section
What is Site Reliability Engineering?
Site Reliability Engineering is a discipline that applies software engineering principles to operations and infrastructure management to improve reliability, scalability, and efficiency.
Why do businesses need Site Reliability Engineering?
Businesses need SRE to reduce downtime, improve customer experiences, automate operations, and support scalable digital services.
How is SRE different from traditional IT operations?
SRE emphasizes automation, engineering practices, measurable reliability objectives, and continuous improvement, while traditional operations often rely more heavily on manual processes.
What are Service Level Objectives?
Service Level Objectives are measurable reliability targets that define expected service performance and availability levels.
What is an error budget?
An error budget represents the acceptable amount of service unreliability within a specific period and helps balance innovation with stability.
Does every organization need SRE?
Any organization operating critical digital services can benefit from SRE practices, especially those managing complex systems and customer-facing applications.
Which skills are important for becoming an SRE professional?
Important skills include Linux administration, networking, programming, cloud computing, automation, monitoring, incident management, and reliability engineering principles.
Can small businesses adopt SRE practices?
Yes. Small businesses can implement foundational SRE practices such as monitoring, automation, incident management, and reliability measurement without large operational teams.
How does SRE improve customer satisfaction?
SRE improves system availability, performance, and stability, reducing service disruptions and creating better user experiences.
Is automation mandatory in SRE?
Automation is a fundamental component of SRE because it reduces manual effort, minimizes errors, and improves operational consistency.
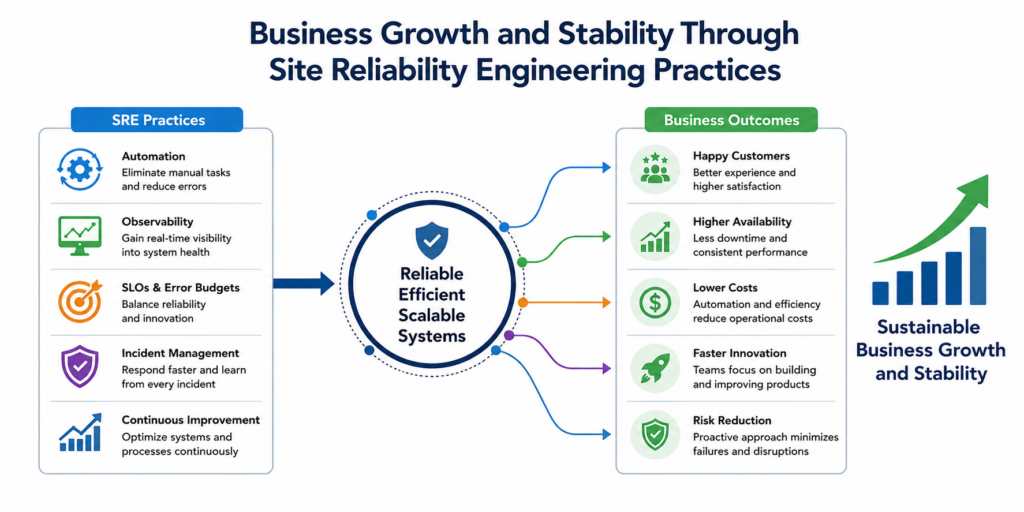
Final Summary
Modern businesses depend on reliable digital systems to support customers, employees, partners, and revenue-generating operations. As technology environments become increasingly complex, maintaining reliability through traditional operational approaches becomes more difficult. Site Reliability Engineering provides a structured framework that combines software engineering, automation, observability, and operational excellence to address these challenges effectively.
Organizations that embrace SRE gain significant advantages, including improved service availability, faster incident resolution, better scalability, reduced operational costs, and enhanced customer satisfaction. At the same time, SRE promotes a culture of accountability, continuous improvement, and data-driven decision-making. By understanding concepts such as SLIs, SLOs, error budgets, automation, and observability, businesses can build resilient systems capable of supporting long-term growth.