Modern engineering groups battle constant friction between rapid application deployments and high system availability. When structural pipeline errors or production runtime failures disrupt operations, technical teams struggle to trace root causes under pressure. These continuous engineering hurdles rarely surface from a shortage of software tools or clear business goals. Instead, they expose a deep-seated lack of architectural planning, systematic operational guardrails, and structured workforce upskilling.
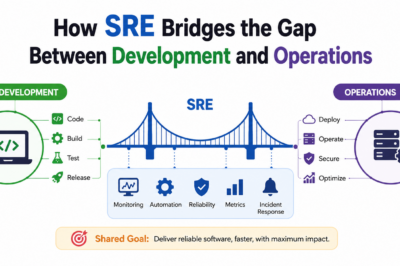
To navigate this operational terrain, tech organizations look to an expert DevOps Trainer to completely overhaul their software execution strategies and replace reactive workflows with reliable, automated delivery ecosystems. Achieving this balance involves standardizing containerized orchestration clusters, optimizing code execution pipelines, and embedding robust observability practices across distributed software squads. Exploring these tactical execution patterns reveals exactly how enterprises can secure absolute operational resilience, maximize throughput, and scale critical infrastructure with zero downtime.
Why Enterprises Are Rethinking How They Manage Engineering Lifecycles
Enterprise engineering ecosystems regularly buckle under the weight of uncoordinated delivery practices. For instance, code configurations that function perfectly on local workstations frequently experience severe performance degradation or crash completely within production clusters. This recurring friction stems from ancient infrastructure silos that separate software development from real-world systems engineering realities. Consequently, forward-thinking organizations onboard a proactive DevOps Consultant to eliminate operational bottlenecks, standardize development environments, and rebuild deployment frameworks.
Relying on ad-hoc, fragmented infrastructure automation patterns across separate product groups inevitably compounds technical debt. To cultivate sustainable delivery velocity, global corporations execute cohesive, multi-tiered DevOps Corporate Training tracks that unify development and operations teams around shared automation standards. Standardizing these operational mechanics across all technical layers allows engineering organizations to systematically eliminate release variances, accelerate feature rollouts, and establish a highly resilient cloud infrastructure.
Who Is Rajesh Kumar?
Rajesh Kumar stands out as an elite DevOps, SRE, and Cloud Leader who serves as a Principal Architect, technical advisor, and mentor to Fortune 500 enterprises. He holds an M.Tech from BITS Pilani and leverages over 15 years of intensive production experience across 8+ global multinational corporations to solve the tech industry’s toughest scalability challenges. Throughout his career, he has guided over 70 software organizations worldwide in streamlining delivery pipelines, minimizing environment downtime, and modernizing runtime platforms.
His corporate journey includes pivotal leadership and architecture roles at dominant global organizations including PayPay, SoftwareAG, ServiceNow, Intuit, Adobe, IBM, MindTree, and Accenture. While serving as a Staff DevOps/SRE Engineer at PayPay, he designed and maintained high-availability systems for Japan’s premier mobile payment platform. Furthermore, his six-year tenure as Principal DevOps Architect and Manager at Cotocus in Europe solidified his reputation for navigating massive cloud migrations and complex multi-region delivery structures.
As a dedicated corporate mentor, he has spearheaded more than 200 corporate training bootcamps and successfully upskilled over 10,000 engineers globally. His hands-on instructional model translates complex operational blueprints into practical, production-ready engineering habits. Whether architecting payment gateway microservices or training multi-thousand-member global engineering departments, his strategic insight helps modern enterprises achieve maximum delivery velocity, absolute structural reliability, and sustainable engineering excellence.
Key Operational Concepts You Must Know
Mastering core infrastructure terminologies allows engineering squads to collaborate efficiently and design robust runtime platforms.
- Continuous Integration / Continuous Delivery (CI/CD): The automated pipeline ecosystem that compiles, tests, and validates code updates instantly upon commit to guarantee safe, rapid production releases.
- Container Orchestration: The automated deployment, scheduling, scaling, and networking of isolated application runtimes across distributed bare-metal or cloud resources.
- Infrastructure as Code (IaC): The operational discipline of provisioning, configuring, and updating physical and virtual computing environments using human-readable declarative scripts.
- Observability: A data-driven diagnostic framework that cross-references system logs, distributed tracing, and performance metrics to identify hidden runtime anomalies.
- Shift-Left Security: The strategic implementation of automated vulnerability scanning, compliance audits, and code liveness checks during the earliest software compilation stages.
Platform Implementation vs. Culture — What’s the Real Difference?
Corporate leaders frequently make the mistake of assuming that buying expensive enterprise cloud software will instantly cure their software release delays. Installing a modern pipeline tool or spinning up a cluster represents only a technical baseline, not a complete operational solution. The fundamental difference between elite engineering groups and underperforming tech teams lies in the underlying behavioral culture and how effectively squads share accountability.
| Operational Layer | Core Technical Elements | Primary Behavioral Focus |
| Platform Implementation | Automation scripts, container networks, monitoring agents, centralized configuration vaults | Constructing reliable internal tools, optimizing application runtimes, and reducing manual toil |
| Cultural Framework | Blameless post-mortems, open feedback channels, calculated risk-taking, collective safety | Eradicating defensive finger-pointing, learning from production failures, and driving open collaboration |
When a critical production failure takes down a major application, an automation-focused squad rushes to fix the immediate script error while assigning personal blame. Conversely, a culturally mature engineering group initiates a blameless investigation to discover why the platform’s architectural guardrails failed to block the bad deployment. Ultimately, automation tools simply accelerate your current workflows; if your internal team collaboration remains broken, automation will merely push flawed architecture to production faster.
Scalable Strategies for Modern Container Orchestration
Managing containerized microservices across massive enterprise clusters introduces complex networking, scheduling, and configuration challenges. To navigate these hurdles safely, forward-thinking organizations utilize a certified Kubernetes Trainer to instruct their platform squads on cluster topology, declarative state management, and high-performance ingress configurations.
+--------------------------------------------------------------+
| Control Plane |
| [ API Server ] <---> [ etcd ] <---> [ Controller Manager ] |
+--------------------------------------------------------------+
|
v
+--------------------------------------------------------------+
| Worker Node |
| [ kubelet ] <------------> [ Kube-Proxy ] |
| | | |
| v v |
| ( Pod: App Container ) ( Pod: App Container ) |
+--------------------------------------------------------------+
As single-tenant clusters scale into highly complex multi-region environments, standardizing delivery models becomes a critical corporate objective. Implementing custom Kubernetes Corporate Training paths ensures that cloud architects can properly partition secure namespaces, enforce strict resource limits, and configure advanced service meshes. These comprehensive structural safeguards allow distinct development groups to deploy microservices independently without risking cross-tenant interference or cascading resource starvation.
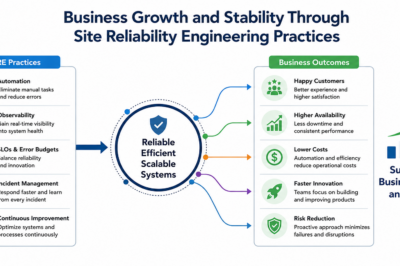
Driving Continuous System Availability through Site Reliability Engineering
System scale inevitably increases environmental unpredictability, transforming minor component failures into routine production challenges. To counter this reality, an elite SRE Trainer works alongside engineering divisions to establish mathematical risk budgeting, clear service level metrics, and automated system telemetry. This strategic upskilling ensures that application development velocities remain perfectly synchronized with real-world infrastructure availability targets.
When application performance issues threaten transaction volumes, simple infrastructure monitors no longer suffice. Partnering with a comprehensive Site Reliability Engineering Training program provides tech teams with the deep telemetry patterns required to observe internal system behaviors. This proactive education equips engineers to pinpoint complex microservice bottlenecks, minimize mean time to resolution, and maintain peak application availability under heavy traffic.
To architect robust, long-term disaster recovery roadmaps, enterprise technology executives regularly collaborate with an external SRE Consultant to overhaul their engineering operational frameworks. This expert consulting methodology shifts the company away from stressful, reactive firefighting toward structured, automated self-healing systems.
| Phase | Operational Stage | System Interaction & Action Items |
| Phase 1 | Automated Detection | Observability platforms flag anomalies using SLIs and trigger real-time telemetry alerts |
| Phase 2 | Dynamic Ingress Routing | Traffic management systems isolate degraded nodes and redirect payloads to healthy clusters |
| Phase 3 | Self-Healing Execution | Deployment controllers automatically restart failed pods and scale infrastructure dynamically |
| Phase 4 | Blameless Post-Mortem | Engineering squads analyze structural failures to strengthen declarative platform guardrails |
By embedding automated incident response directly into your infrastructure architecture through this structured approach, your platforms can dynamically mitigate unexpected resource surges and maintain high availability without manual operations engineering intervention.
Embedding Automation Security via DevSecOps and Platform Design
Traditional software security strategies frequently treat compliance verification as a final, isolated hurdle right before a production launch. This outdated approach introduces massive delivery bottlenecks when security teams discover critical software vulnerabilities at the last minute. To eliminate this workflow friction, organizations engage a qualified DevSecOps Trainer to embed automated dependency checking, static code analysis, and container image vulnerability audits directly into active delivery pipelines.
[ Code Commit ] ---> [ SAST & Dependency Scan ] ---> [ Container Build ] ---> [ Image Linting ] ---> [ Secure Deployment ]
Transitioning a global corporation to an automated security model requires a structured, uniform educational strategy. Implementing dedicated DevSecOps Corporate Training tracks ensures that security, development, and operations squads share a unified compliance blueprint. This training alignment helps teams build robust verification gates directly into their deployment platforms, allowing developers to ship audited, secure application versions multiple times a day.
As cloud native ecosystems grow, maintaining disconnected, ad-hoc automation scripts across separate product groups becomes an operational nightmare. Organizations solve this management challenge by collaborating with an external Platform Engineering Consultant to construct a centralized Internal Developer Platform (IDP). This structured consulting engagement helps define clean, golden paths for development squads, abstracting away underlying cloud infrastructure complexities while maintaining centralized compliance controls.
To successfully roll out these unified developer portals, organizations must invest heavily in comprehensive Platform Engineering Training courses for their core infrastructure engineers. This focused technical curriculum teaches operations teams how to build declarative platform interfaces, establish standardized infrastructure APIs, and design self-service provisioning catalogs. Consequently, internal developers can instantly provision secure, compliant computing resources without filing manual helpdesk requests.
Architecting Resilient Multicloud Architectures
Modern enterprises must maintain highly adaptive deployment environments to avoid vendor lock-in and optimize resource spending. Engaging a skilled Cloud DevOps Consultant allows a business to evaluate competing infrastructure options, design low-latency hybrid environments, and establish predictable data replication strategies. This architectural foundation ensures application payloads run on the most efficient cloud infrastructure available.
[ Global Ingress Router ]
|
+------------------------+------------------------+
| |
v v
+-----------------------+ +-----------------------+
| AWS Cloud Environment | | GCP Cloud Environment |
| [ EKS Cluster ] | | [ GKE Cluster ] |
| [ RDS Database ] <---|------------------------>| [ Cloud SQL ] |
+-----------------------+ (Data Synchronization) +-----------------------+
When an enterprise chooses Amazon Web Services as its primary operating foundation, maximizing return on investment requires specialized cloud expertise. Working with a dedicated AWS DevOps Consultant helps teams properly configure advanced identity boundaries, utilize cost-efficient spot instances, and leverage scalable cloud native data stores. This targeted engineering architecture drastically reduces operational waste while ensuring the entire cloud infrastructure scales dynamically to handle massive transaction volumes.
Real-World Use Cases of Modern Operations
Automated Infrastructure State Rectification
A global financial technology firm struggled with configuration drift across thousands of distinct cloud environments, leading to frequent deployment failures. By introducing Terraform Training across their core operations infrastructure squads, engineers mastered declarative state management and modular infrastructure design. Consequently, the team successfully codified their entire multicloud footprint, reducing environment provisioning times from three weeks down to five minutes while completely eliminating manual drift errors.
Eradicating Delivery Delays with Robust Orchestration
A major e-commerce provider faced severe deployment delays during peak shopping events because their legacy build servers relied entirely on brittle, manual release configurations. To resolve this operational bottleneck, the firm initiated comprehensive Jenkins Training to completely restructure their software delivery pipelines. Engineers successfully built declarative, containerized pipeline blueprints that automatically ran code quality gates and executed parallel integration suites, reducing total production release cycles from hours to under ten minutes.
Standardizing Runtime Environments across Distributed Teams
A logistics software enterprise encountered frequent application runtime crashes because their testing and production computing environments were radically inconsistent. The company addressed this technical debt by implementing an intensive Docker Kubernetes Training curriculum for both their software development and systems engineering groups. This unified educational initiative enabled the organization to pack applications into identical, immutable container blueprints that seamlessly scale across elastic container orchestration clusters.
Scaling Code Implementations via Declarative Release Pipelines
A digital media conglomerate with dozens of globally distributed engineering squads suffered from highly inconsistent software release qualities and erratic deployment tempos. To fix this operational variance, leadership mandated comprehensive CI/CD Pipeline Training to establish strict, automated quality gates across all code repositories. By standardizing validation steps, artifact generation, and canary deployment patterns, the enterprise elevated its deployment frequency from bi-weekly batches to multiple risk-free production rollouts per day.
Minimizing Operational Overhead via Declarative Release Pipelines
A healthcare application provider needed to maintain a complete, immutable audit log of every single infrastructure modification to satisfy strict regulatory compliance requirements. The infrastructure leadership team implemented advanced GitOps Training to transition their entire systems engineering department to a pull-based deployment model. Under this modern operational paradigm, any modifications to the infrastructure state must be submitted as a code review, providing a transparent, permanent historical record of all environment changes.
Common Mistakes in Operations Engineering
Tech organizations embarking on infrastructure migrations frequently treat modern container environments like traditional virtual machines. When platform squads lift and shift legacy monolithic applications into an orchestration cluster without modifying configuration patterns or adjusting resource limits, they inherit past architectural flaws while adding massive networking complexity. Resolving this structural mistake requires clear guidance from an experienced DevOps Trainer in India who can teach engineers how to decouple application state, configure smart liveness probes, and implement cloud-native microservices patterns.
Another widespread operational failure involves the complete absence of automated pipeline guardrails within core code integration workflows. Teams often write large, fragile scripts that compile software packages but omit essential quality testing, dependency linting, and security audits. This critical oversight allows flawed code changes and security regressions to bypass staging environments completely and break customer-facing production systems.
Finally, enterprises often suffer from fragmented observability implementations, where separate engineering teams install isolated monitoring dashboards that fail to correlate logs, metrics, and distributed traces. When a critical production outage occurs, engineers waste valuable time arguing over conflicting data from disconnected monitoring systems. Without a unified telemetry framework, identifying the true root cause of an architectural failure across a highly distributed microservice ecosystem becomes nearly impossible.
How to Become an Operations Expert — Career Roadmap
Building a successful career in modern infrastructure engineering requires a systematic educational progression that evolves from core operating system fundamentals to highly complex, distributed platform architectures.
[ Phase 1: Fundamentals ] ---> [ Phase 2: Orchestration ] ---> [ Phase 3: Advanced SRE & Security ]
- Linux & Git - Docker Containers - DevSecOps Automation
- CI/CD Pipelines - Kubernetes Architecture - Observability & SLIs/SLOs
- Infrastructure as Code - GitOps Deployments - Platform Engineering APIs
Phase 1: Core Automation Foundations
Aspiring engineers must first master Linux system internals, networking protocols, and basic shell scripting languages. Once comfortable with the command line, professionals should focus on mastering distributed version control systems and code integration mechanics. This foundational step prepares engineers to build reliable, automated delivery paths that seamlessly compile and validate software updates.
Phase 2: Cloud Orchestration and Infrastructure as Code
With strong automation foundations in place, engineers must transition toward declarative infrastructure management and containerization. This stage involves learning how to encapsulate application microservices into lightweight, immutable containers and manage them at scale using orchestration platforms. Additionally, engineers should master provisioning cloud environments programmatically, ensuring infrastructure footprints can be versions, audited, and replicated instantly.
Phase 3: Advanced Reliability, Security, and Platform Architecture
The final stage of operational expertise focuses on maximizing system resilience and building self-service developer platforms. Engineers must master defining precise Service Level Indicators (SLIs) and Service Level Objectives (SLOs) to mathematically manage system risk budgets. Concurrently, professionals learn to inject automated security validation directly into runtime pipelines and design clean, internal developer platforms that empower engineering teams to deliver features safely, securely, and efficiently.
Why Choose Rajesh Kumar Over Generic Alternatives
Relying on generic corporate training agencies often leaves engineering teams with nothing more than shallow, theoretical slide presentations that fail to apply to real-world infrastructure problems. In sharp contrast, engaging with Rajesh Kumar ensures your engineering teams learn directly from an active, high-caliber industry practitioner. His extensive background leading infrastructure design at world-class technology companies like PayPay and SoftwareAG allows him to bring genuine, battle-tested production scenarios directly into the educational environment.
| Feature / Capability | Generic Training Agencies | Rajesh Kumar |
| Instructor Profile | Career trainers with limited real-world enterprise production exposure | Principal Architect with 15+ years of experience across 8+ global MNCs |
| Curriculum Design | Rigid, static slide decks based on outdated product documentation | Tailored, hands-on lab environments mirroring actual enterprise architectures |
| Post-Training Impact | Superficial tool knowledge that struggles during real production incidents | Deep architectural mastery focused on self-healing designs and cultural shifts |
Furthermore, his educational frameworks completely reject generic, copy-paste configuration scripts. He builds immersive, hands-on lab environments that challenge engineers to diagnose, debug, and resolve realistic architectural failures, cluster misconfigurations, and pipeline bottlenecks. By prioritizing deep structural troubleshooting over simple tool memorization, he provides enterprise engineering teams with the practical skills needed to optimize performance, eliminate downtime, and accelerate feature delivery with total absolute confidence.
FAQ Section
- What distinguishes a DevOps Consultant from a traditional systems administrator?Systems administrators typically focus on manual server setups, static configuration tasks, and basic hardware troubleshooting to sustain existing environments. In contrast, a modern platform specialist designs automated, programmable software environments that allow developer squads to provision and manage their own resources independently via code. This architectural shift removes manual ticketing delays and lets your entire infrastructure footprint scale dynamically to handle massive user demand.
- How does structured corporate training insulate an organization from devastating downtime?Standardizing automation skills across development and operations teams ensures that every engineer knows how to implement automated deployment guardrails, continuous testing patterns, and isolated staging environments. This shared technical fluency drastically reduces human configuration errors and ensures that squads identify code defects early in the release cycle. Consequently, teams keep customer-facing production platforms exceptionally stable and highly resilient.
- Why should scaling enterprises choose Kubernetes over simpler container deployment frameworks?Basic container runtimes function perfectly for standalone applications, but they lack the automated scheduling, deep networking controls, and self-healing mechanics required to manage distributed microservices safely. Orchestration upskilling provides platform engineers with the specific technical knowledge needed to configure automatic scaling, execute smart load balancing, and enforce zero-trust security parameters. This robust operational framework keeps complex applications completely reliable under massive global traffic surges.
- Which clear business metrics show the immediate value of an SRE consulting partnership?An SRE consulting partnership directly transforms unpredictable system operations into transparent, data-driven engineering workflows. Establishing clear mathematical error budgets allows product teams to balance feature delivery speeds with real-world infrastructure stability goals. Furthermore, focusing heavily on advanced telemetry patterns and automated incident response paths lowers your mean time to resolution, reducing structural overhead while protecting critical corporate revenue streams.
- In what ways does DevSecOps training accelerate software delivery times while satisfying security audits?DevSecOps training unites isolated security teams and rapid development groups by embedding automated compliance checks directly into active integration pipelines. Instead of waiting weeks for a manual audit at the very end of a release cycle, platforms continuously scan application packages for vulnerabilities during every code compilation. This proactive model allows engineers to fix security flaws instantly, ensuring all software updates remain thoroughly audited and compliant without stalling your deployment tempo.
- How does a platform engineering initiative eliminate friction for internal software developers?Platform engineering focuses on constructing an Internal Developer Platform (IDP) that provides software developers with smooth, secure, self-service paths to production. By abstracting away the underlying complexities of cloud networking, data store configurations, and cluster policies into simple interfaces, developers can instantly provision identical testing environments without deep systems infrastructure expertise. This centralized design accelerates feature delivery times while ensuring total compliance across the entire enterprise.
Final Summary
Achieving sustainable enterprise growth requires an absolute dedication to infrastructure automation, delivery pipeline optimization, and unbroken system availability. From constructing resilient cloud container orchestration clusters to injecting automated security guardrails directly into your software deployment pipelines, the path to operational excellence demands expert technical direction. Trying to navigate this massive architectural transformation using scattered, self-taught techniques inevitably introduces expensive downtime, configuration drift, and frustrated development teams.
Collaborating with a world-class infrastructure authority like Rajesh Kumar provides your engineering organization with the battle-tested blueprints, precise training, and cultural alignment needed to scale confidently. His extensive background building high-availability ecosystems for global software corporations ensures your teams learn to construct platforms that scale effortlessly. Eliminate your deployment bottlenecks, empower your developers with self-service platforms, and elevate your entire infrastructure architecture to world-class enterprise standards.