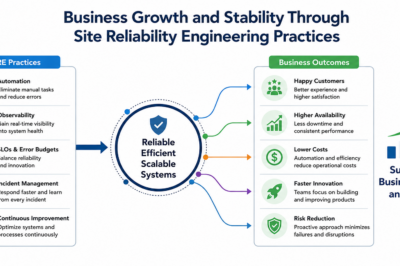
Site Reliability Engineering bridges the gap between software development and IT operations to build highly scalable, ultra-reliable systems. When engineering teams prioritize system health, they directly eliminate the friction that users face during unexpected outages or slow page loads. Modern digital applications require continuous care, and that is precisely where a structured approach to stability creates a competitive advantage.
Therefore, organizations must transform how they monitor, manage, and scale their infrastructure to match growing user demands. Implementing these methodologies allows teams to predict failures before they impact the end user, ensuring a seamless digital environment. For those looking to master these modern operational methodologies, specialized training programs at Sreschool provide the practical hands-on engineering skills needed to excel in this highly demanding field.
Key Operational Concepts You Must Know
Understanding Service Level Objectives and Indicators
Service Level Indicators function as the fundamental metrics that quantify the real-time performance of your production architecture. For instance, you might measure the latency of a specific API endpoint or the error rate of your authentication microservice. These granular measurements provide the objective raw data necessary to understand exactly how your software behaves under heavy user loads.
Consequently, you use these indicators to define your Service Level Objectives, which represent the target reliability goals for your platforms. An objective might dictate that ninety-nine percent of all successful database queries must return a response in less than two hundred milliseconds. Maintaining this target ensures that your engineering team aligns its daily operational efforts with actual user expectations.
[ Service Level Indicator ] ---> The raw metric (e.g., Latency = 150ms)
|
v
[ Service Level Objective ] ---> The target goal (e.g., 99% of requests < 200ms)
|
v
[ Error Budget ] ---> The allowable room for failure (e.g., 1% room)
Managing the Error Budget Effectively
The error budget represents the exact amount of instability your business can safely tolerate over a specific compliance window. If your reliability goal is set to ninety-nine percent, your team possesses a one percent budget for intentional risk, deployments, and experimentation. This budget acts as a formal contract between product managers who desire rapid feature releases and engineers who protect system stability.
Furthermore, running out of your designated budget immediately triggers an automated or procedural halt on all new feature deployments. When this occurs, your entire team shifts focus exclusively to fixing bugs, optimizing infrastructure, and rewriting unstable application code. This systematic approach removes the emotional arguments from deployment decisions and enforces operational discipline across the organization.
The True Cost of Infrastructure Downtime
Unplanned infrastructure outages introduce massive financial liabilities that extend far beyond the immediate loss of transactional revenue during the event. Systems that experience frequent failure actively degrade customer trust, driving frustrated users directly into the arms of your closest competitors. Additionally, your engineering teams waste valuable time fighting fires instead of building innovative features that drive business growth.
Ultimately, preventing downtime requires a proactive investment in automated testing, continuous monitoring, and self-healing architectural patterns. By calculating the precise cost of an hour of outage, organizations quickly realize that building resilient systems saves millions in the long run. Reliability is not an afterthought; it is a core feature that dictates the overall market survival of modern digital enterprises.
Platform Implementation vs. Culture — What’s the Real Difference?
The Mechanics of Platform Tools
Platform implementation focuses heavily on the deployment of specific software tools, automated pipelines, and cloud infrastructure frameworks. Engineers spend their time configuring continuous integration workflows, orchestrating container environments, and building comprehensive observability dashboards to track system performance. These technological solutions provide the necessary scaffolding for running highly available modern applications.
However, simply purchasing advanced software licenses or installing complex monitoring agents will not automatically guarantee a reliable system. Tools are inherently passive instruments that require precise configuration, continuous updates, and intelligent human interaction to deliver real operational value. Without a deeper structural understanding, complex toolchains often create additional layers of confusion during critical production incidents.
Nurturing a Resilient Engineering Culture
A true reliability culture shifts the organizational mindset from pointing fingers during failures to collectively solving complex systemic problems. Teams must embrace a blameless philosophy that views every production incident as a valuable learning opportunity rather than a reason for punishment. This psychological safety encourages engineers to speak up early about structural vulnerabilities before they escalate into catastrophic customer outages.
Moreover, a healthy culture encourages shared responsibility where developers actively participate in the ongoing operational health of their software. When code creators share the burden of on-call rotations, they naturally write more resilient, observable, and easily maintainable applications. Culture binds your people together, transforming isolated engineering tasks into a unified mission focused on customer satisfaction.
| Characteristic | Platform Implementation (Tools) | Engineering Culture (Mindset) |
|---|---|---|
| Primary Focus | Automation, dashboards, and cloud infrastructure configuration. | Shared responsibility, psychological safety, and continuous learning. |
| Success Metric | Number of pipelines automated or tools successfully deployed. | Reduced time to acknowledge incidents and systemic improvements made. |
| Failure Response | Triggering automated alerts and generating diagnostic log reports. | Conducting blameless post-mortems to discover root technical causes. |
| Ownership | Often restricted to specialized infrastructure or DevOps teams. | Distributed across all software development and operations squads. |
Real-World Use Cases of Modern Operations
Optimizing High-Traffic E-Commerce Platforms
During massive seasonal retail events, e-commerce platforms experience sudden, unprecedented surges in concurrent user traffic that threaten database stability. Operational experts mitigate these risks by configuring aggressive edge-caching layers and deploying horizontal auto-scaling groups that dynamically adjust server capacity. These proactive architectural changes prevent the checkout systems from crashing when thousands of shoppers attempt to purchase items simultaneously.
Additionally, implementing graceful degradation strategies ensures that minor failures do not bring down the entire shopping experience. For example, if the personalized recommendation engine slows down under intense load, the platform can automatically disable it while keeping the search and payment loops fully functional. This specific design choice preserves core business functionality and protects revenue streams during peak monetization windows.
Scaling Financial Transaction Systems
Financial networks demand absolute data consistency, low latency, and zero tolerance for message loss during high-volume processing periods. Engineers achieve this by deploying distributed consensus databases and implementing strict dead-letter queues to handle malformed payment requests safely. Every single transaction must be traceable, requiring highly optimized logging mechanisms that capture state changes without degrading system throughput.
Furthermore, continuous chaotic injection testing allows financial institutions to simulate localized cloud region failures safely within production environments. By deliberately severing connection paths between data centers, teams verify that automated failover mechanisms route transactions instantly without manual human intervention. This rigorous verification process builds immense confidence that the financial system will remain stable during actual hardware network disasters.
Common Mistakes in Operations Engineering
Falling into the Trap of Alert Fatigue
Configuring overly sensitive monitoring thresholds fills engineering communication channels with a continuous stream of low-priority, non-actionable alert messages. When humans receive hundreds of notifications every hour, they naturally begin to ignore the noise to preserve their own sanity. Consequently, when a genuine, critical production failure finally occurs, it is frequently overlooked amidst the overwhelming mountain of irrelevant warnings.
[ Too Many Low-Priority Alerts ] ---> [ Engineers Overwhelmed ] ---> [ Real Issues Ignored ]
To fix this dangerous problem, teams must ensure that every triggered alert links directly to a documented, actionable runbook. If an alert does not require immediate human intervention to prevent user impact, it should be categorized as a non-urgent ticket instead. Refining your alerting system protects your team from burnout and ensures rapid responses to genuine emergencies.
Over-Engineering Systems Too Early
Young engineering organizations often complicate their software architectures prematurely by adopting distributed microservices when a simple monolithic structure would suffice. Managing hundreds of containers, complex service meshes, and distributed databases requires massive operational overhead that small teams cannot sustain. This unnecessary complexity slows down feature delivery and introduces a vast web of hidden failure points that are incredibly difficult to debug.
Therefore, you should focus on building the simplest possible architecture that successfully satisfies your current business and reliability requirements. Scale your systems organically as your user base expands, rather than trying to solve hypothetical problems you might never actually encounter. Simplicity remains the ultimate guiding principle when designing highly reliable, cost-effective digital platforms.
How to Become an Operations Expert — Career Roadmap
Mastering Core Foundations
The journey toward becoming a world-class operations specialist begins with an unyielding curiosity about computer science fundamentals. You must develop a deep, practical understanding of operating system internals, including memory allocation, process management, and file systems. This structural knowledge forms the foundation upon which all modern cloud infrastructure and distributed applications are built.
- Learn Linux Internals: Focus on mastering system calls, kernel parameters, and understanding how processes utilize underlying hardware resources.
- Understand Networking Protocols: Deeply study the transport layer, routing mechanisms, domain name systems, and how packets traverse complex global networks.
- Practice Scripting Languages: Gain proficiency in automation programming using languages like Python or Go to eliminate repetitive manual system tasks.
Embracing Advanced Cloud Architecture
As you progress, shift your educational focus toward modern cloud infrastructure design, containerization, and comprehensive continuous deployment methodologies. You must learn how to treat infrastructure as software code by utilizing declarative configuration tools to provision global networks. This transition enables you to build predictable, reproducible environments that eliminate the classic issue of software working only on a developer’s local machine.
- Study Container Orchestration: Learn how to deploy, manage, scale, and secure complex containerized workloads using industry-standard platforms.
- Master Observability Frameworks: Discover how to collect, aggregate, and analyze distributed traces, structured logs, and system metrics effectively.
- Implement Chaos Engineering: Practice intentionally injecting controlled failures into your staging environments to discover hidden architectural weaknesses early.
FAQ Section
- What is the primary difference between standard DevOps and Site Reliability Engineering?
DevOps focuses broadly on breaking down barriers between development and operations teams, while SRE applies specific software engineering principles directly to solve infrastructure and reliability challenges.
- How do you calculate an error budget for an application?
You calculate an error budget by subtracting your target Service Level Objective percentage from one hundred percent, leaving you with the exact allowed margin for system failure.
- Why is a blameless post-mortem culture important for modern engineering teams?
A blameless post-mortem culture ensures that teams focus entirely on discovering systemic technical vulnerabilities and process gaps rather than wasting time assigning personal fault to individual engineers.
- Can small startups benefit from implementing these advanced reliability concepts early on?
Yes, startups benefit immensely by adopting fundamental practices like structured logging, basic monitoring, and simple automation, which prevent chaotic technical debt as the business begins to scale rapidly.
- What are the most critical metrics to track for user experience?
The most critical metrics include application response latency, request error rates, overall system throughput, and the total duration of unresolved production availability incidents.
Final Summary
Prioritizing availability, optimizing system performance, and cultivating a resilient engineering mindset collectively form the cornerstone of any successful modern digital enterprise. When organizations treat operational health as an essential feature rather than an afterthought, they protect their revenue streams and secure long-term user loyalty. Systems will inevitably experience hardware glitches, network anomalies, and unexpected software bugs as they grow larger and more complex.
However, by utilizing clear metrics, eliminating operational waste, and continuously upskilling engineering talent, teams transform these chaotic challenges into predictable, manageable events. Investing systematically in robust engineering principles guarantees that your platform will remain strong, scalable, and fully prepared to deliver delightful experiences to every user around the world.