Introduction
Site Reliability Engineering (SRE) has become one of the most sought-after career paths in the IT industry. It represents a fundamental shift in how organizations approach system reliability, combining software engineering principles with operational excellence. For IT professionals looking to advance their careers, understanding the SRE landscape offers a pathway to roles that are both technically challenging and strategically important. Sreschool provides comprehensive training programs designed to help IT professionals navigate this career transition successfully. The SRE field bridges the gap between traditional operations and modern software development, creating opportunities for professionals from diverse technical backgrounds to build rewarding careers focused on keeping critical systems running smoothly.
What Exactly Is Site Reliability Engineering?
SRE is a discipline that applies software engineering principles to infrastructure and operations problems . At its core, SRE treats operations as a software problem that can be solved through automation and engineering rather than manual processes. This approach was pioneered by Google and has since been adopted by organizations worldwide as they recognize the need for more systematic approaches to system reliability.
The role of an SRE is to ensure that critical systems remain reliable, scalable, and performant while enabling rapid feature development . Unlike traditional operations roles that often focus on reactive firefighting, SRE takes a proactive approach to reliability. SREs spend roughly 50% of their time on operational work (incidents, monitoring, manual tasks) and 50% on engineering projects (automation, tool building, system improvements) . This balance ensures that teams focus on long-term reliability improvements rather than just reactive maintenance.
Modern SREs work at the intersection of development and operations, building systems that let companies run smoothly and faster . They design and maintain the backbone of technology products, automate the work that slows down engineers, and monitor the signals that show whether a product is healthy or in distress .
Key Operational Concepts You Must Know
Understanding the foundational concepts of SRE is essential for anyone pursuing this career path. These concepts form the bedrock of SRE practice and differentiate it from traditional operations approaches.
Service Level Indicators (SLIs), Service Level Objectives (SLOs), and Service Level Agreements (SLAs)
SLIs are quantitative measures of service performance. Common SLIs include request latency, error rates, throughput, and availability percentages . SLOs are targets for these indicators, specifying the acceptable level of performance. For example, an SLO might specify that 99.9% of requests must complete within 200 milliseconds . SLAs are formal agreements between service providers and customers that outline consequences if SLOs are not met.
These concepts are crucial because they provide objective measures of reliability that can be used to make business and technical decisions . They help organizations balance innovation with stability by establishing clear reliability targets that everyone understands.
Error Budgets and Risk Management
The concept of error budgets is fundamental to SRE practice. An error budget is essentially the allowable margin of error within an SLO. If a service has a 99.9% availability SLO, the error budget is 0.1%—the amount of unreliability that is acceptable to users .
Error budgets serve as a powerful tool for balancing innovation and reliability. When the error budget is depleted, teams must prioritize reliability work over feature development until the budget is restored . This creates a data-driven mechanism for making decisions about when to release new features versus when to focus on stability.
Toil and Automation
Toil is the term used in SRE to describe repetitive, manual, interrupt-driven work that offers little long-term value and scales linearly with growth . Examples of toil include manual configuration changes, repetitive password resets, and manually responding to non-actionable alerts.
SRE aims to reduce toil through automation. The industry benchmark suggests that SRE teams should spend no more than 50% of their time on toil and should actively work to reduce that percentage over time . Automation is not just about efficiency—it’s about creating systems that can scale without requiring proportional increases in human effort.
Incident Management and Post-Mortems
Incident management in SRE follows structured processes designed to minimize downtime and learn from failures . This includes clear incident response procedures, effective communication during incidents, and blameless post-mortems after incidents are resolved .
Blameless post-mortems are a key practice in SRE culture. They focus on understanding why systems failed and how to prevent future failures, rather than assigning blame to individuals . This approach encourages honest discussion about incidents and helps build a learning culture within organizations.
Observability
Observability goes beyond traditional monitoring by providing deep insight into system behavior through three pillars: metrics, logs, and distributed tracing . While monitoring tells you that something is wrong, observability helps you understand why it’s wrong . Modern observability tools like Prometheus, Grafana, Jaeger, and OpenTelemetry have become essential parts of the SRE toolset .
Platform Implementation vs. Culture — What’s the Real Difference?
One of the most common misconceptions in SRE is that success comes primarily from implementing platforms and tools. Organizations often invest heavily in observability stacks, incident management systems, and automation platforms, expecting these tools to solve their reliability challenges. While tools are essential, they are only part of the equation.
Understanding the Culture Gap
The real difference between platform implementation and culture comes down to mindset and behavior. Platform implementation involves selecting and deploying tools to monitor systems, manage incidents, and automate tasks . Culture, on the other hand, encompasses how teams work together, how they respond to failures, and how they prioritize reliability in their daily work .
Without the right culture, even the best tools fail to deliver their potential . A team with world-class monitoring tools but a blame culture will struggle to learn from incidents. Similarly, teams with comprehensive automation capabilities but no willingness to invest in reducing toil will continue to struggle with manual overhead .
The Membrane Approach
Organizations need what has been described as a “membrane”—a semi-permeable boundary that filters what enters the team’s workflow . This concept is distinct from silos, which are impermeable walls that create bottlenecks and foster “not my problem” cultures . A healthy membrane protects the SRE team from debilitating noise while remaining permeable to genuine needs .
Culture determines how this membrane functions. Teams with blameless cultures encourage open discussion about failures and proactively share knowledge . Teams with healthy SRE cultures prioritize reducing toil, not just managing it. They recognize that reliability is everyone’s responsibility, not just the SRE team’s problem .
Shared Ownership and Cross-Functional Teams
A key cultural element in successful SRE implementations is shared ownership . This means breaking down silos between development and operations teams, building cross-functional teams that work together toward common goals . Many organizations implement DevOps-SRE rotations where developers take on on-call duties under the mentorship of experienced SREs . This helps developers understand operational challenges and encourages them to write more resilient code.
Cultural transformation is often the hardest part of adopting SRE . Organizations that focus exclusively on tools and platforms without addressing cultural barriers find that their SRE implementations fail to deliver expected benefits .
Real-World Use Cases of Modern Operations
Understanding how SRE principles apply in practice helps illustrate the value of this approach. Here are real-world examples of modern operations through the lens of SRE.
Google’s SRE Implementation
SRE was developed at Google to address the challenge of maintaining massive, globally distributed systems . Google’s SRE teams use rigorous SLOs, error budget policies, and automated systems to maintain reliability at scale . This approach has been so successful that it has been adopted by organizations worldwide .
Financial Services Reliability
A global bank employed an SRE team responsible for systems handling millions of transactions daily . The SRE team focused on building systems that let the company run smoothly and faster, using automation to reduce manual toil . The role required engineers who could stay calm when production incidents threatened customers and revenue . This demonstrates how SRE principles apply in highly regulated, mission-critical industries.
Startup Reliability Investment
Some startups are learning to treat observability as a core investment rather than something added after product launch . One startup founder recommends spending 5-15% of the budget on observability while keeping it as lean as possible . This approach uses open source tools like Prometheus and Grafana before jumping into expensive solutions . The focus is on monitoring critical parts of the business, not drowning in noise.
Incident Response Automation
A practical example of SRE in action is automating postmortem creation after high-severity incidents . Teams can implement workflows that automatically create structured postmortem issues when a critical incident is resolved . This ensures consistent incident documentation and helps build a learning culture around failures.
Toil Reduction Success
One organization reduced toil from 83.9% to 44.7% by implementing a systematic approach to filtering work requests . They used visible intake boards to triage incoming requests and built a “membrane” that balanced openness with protection . This transformation compressed their P95 cycle time from 294 days to just 57 days .
Cross-Functional On-Call Rotations
Many organizations have implemented shared on-call rotations where developers and SREs share operational responsibility . This approach uses escalation policies that page SREs first, followed by developers if incidents remain unresolved . This model combines operational expertise with cross-functional awareness and shared responsibility.
Common Mistakes in Operations Engineering
Understanding common mistakes in SRE implementation helps IT professionals avoid pitfalls and build more effective systems. Here are the most frequent errors in operations engineering based on real-world experience.
Mistake 1: Chasing Every Tool Instead of Mastering Fundamentals
New engineers often jump into Kubernetes, Terraform, Prometheus, and dozens of other tools without building depth in the basics . This scattershot approach leads to superficial knowledge of many tools but deep understanding of none. It results in frustration, burnout, and stalled momentum .
Successful SREs focus on building a strong foundation in Linux systems, networking fundamentals, and one or two programming languages before expanding their toolset . They develop deep expertise in core areas rather than surface-level familiarity with everything.
Mistake 2: Ignoring Human Skills
Technical skills alone are insufficient for SRE success . Clear communication under pressure, documenting processes, and working with a team matter just as much as YAML files and pipelines . SREs must explain technical issues to non-technical stakeholders, write concise incident reports, and present reliability work to leadership .
Overlooking these soft skills leads to difficulty collaborating with development teams, poor incident communication, and inability to advocate for reliability investments.
Mistake 3: Treating SRE as a Traditional Ops Role
Some organizations implement SRE teams that function as traditional operations teams with a new name . They focus on reactive firefighting rather than proactive reliability engineering. This approach misses the fundamental shift in mindset that SRE represents.
SRE should be about building systems that solve operational problems at scale . It’s about engineering solutions, not just managing tickets.
Mistake 4: Setting Unrealistic SLOs
Organizations sometimes set SLOs based on what they wish were true rather than what the system can realistically deliver . This leads to constant SLO violations, depleted error budgets, and a culture of ignoring reliability metrics.
SLOs should be ambitious but achievable, based on actual system capabilities and business requirements . They should be refined over time as systems improve.
Mistake 5: Neglecting Documentation
Many teams view documentation as low-value work and fail to invest in it . This leads to knowledge silos, difficulty onboarding new team members, and repeated mistakes. Good documentation is not optional—it’s a critical component of maintaining reliable systems .
Mistake 6: Ignoring the Cultural Dimension
Organizations often implement SRE tools and processes without addressing underlying cultural issues . They maintain blame cultures, reward firefighting behavior, and fail to create shared ownership of reliability . This cultural gap prevents SRE practices from taking root and delivering their full value.
Mistake 7: Applying a Scattershot Job Search Approach
Those entering the SRE field often apply to positions indiscriminately rather than building visibility and networks . Instead of developing a clear story about their skills and value, they hope something sticks. This approach leads to frustration and missed opportunities .
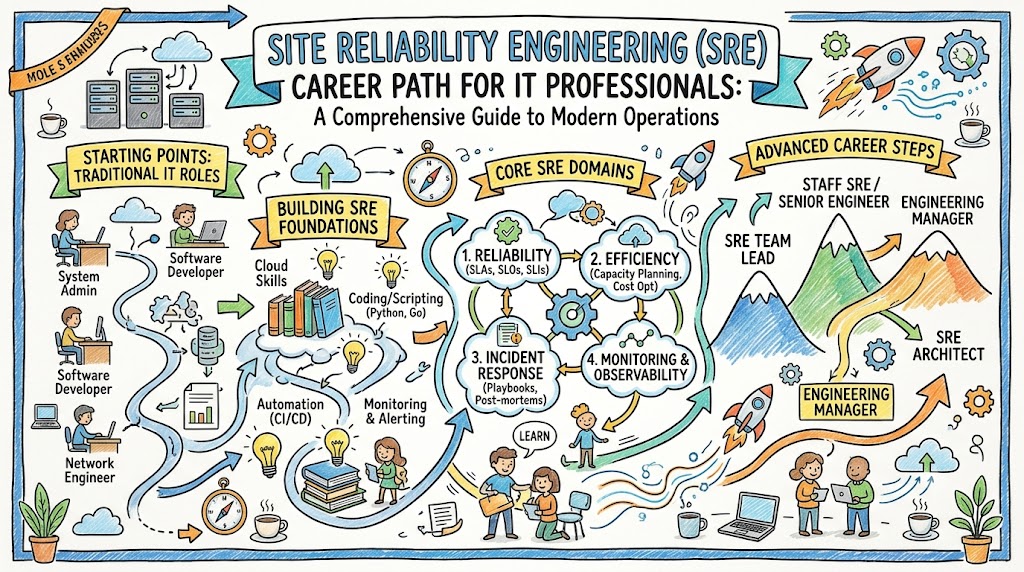
How to Become an Operations Expert — Career Roadmap
Becoming an operations expert through SRE requires a structured approach to learning and career development. Here’s a comprehensive roadmap for IT professionals pursuing this path.
Phase 1: Build Foundation Skills (2-3 Months)
Start with the fundamentals that underpin all SRE work . Master Linux fundamentals and command-line proficiency. Understand networking concepts including TCP/IP, DNS, and load balancing. Learn one or two programming languages well—Python is the most common for SRE automation . Essential topics include:
- Linux system administration and command-line tools
- Basic networking and security principles
- Python or Go programming
- Version control with Git
Phase 2: Learn Cloud and Infrastructure (3-4 Months)
Gain proficiency with cloud platforms like AWS, GCP, or Azure . Understand core compute services, storage solutions, and networking in your chosen cloud. Master Infrastructure as Code with Terraform . Learn containerization with Docker and orchestration with Kubernetes .
Essential skills in this phase:
- Cloud fundamentals on AWS, GCP, or Azure
- Infrastructure as Code with Terraform
- Containerization with Docker
- Orchestration with Kubernetes (CKA certification recommended)
Phase 3: Master Monitoring and Observability (2-4 Months)
Set up monitoring systems with Prometheus and dashboards with Grafana . Implement centralized logging with the ELK stack or similar tools. Learn distributed tracing with Jaeger or OpenTelemetry . Understand SLIs, SLOs, and error budgets in practice .
Focus on:
- Metrics collection with Prometheus
- Visualization with Grafana
- Log management and analysis
- Distributed tracing
Phase 4: Gain Practical Experience (6-12 Months)
Build portfolio projects demonstrating your skills . Create a multi-service application with comprehensive monitoring. Implement automated deployment pipelines. Design and document disaster recovery procedures. Contribute to open source projects . Volunteer for reliability work in your current role .
Practical experience includes:
- Building a personal SRE lab with monitoring and alerts
- Automating CI/CD pipelines
- Participating in incident response and post-mortems
- Contributing to open source infrastructure projects
Phase 5: Develop SRE-Specific Expertise (Ongoing)
Deepen your expertise in advanced topics. Study distributed systems design and fault-tolerant architectures . Learn chaos engineering practices . Understand capacity planning and performance optimization . Practice incident management and on-call procedures .
Advanced areas include:
- Distributed systems principles
- Chaos engineering
- Capacity planning
- Incident management
- Blameless post-mortems
Alternative Entry Paths
From Software Development: Leverage strong programming skills, focus on system administration, monitoring, and incident response . Seek DevOps roles or volunteer for infrastructure projects within your organization .
From System Administration: Build on infrastructure knowledge, develop programming and automation skills, learn cloud platforms, and focus on software engineering principles .
From DevOps Engineering: Expand CI/CD expertise into SRE practices, focus on SLO management, advanced monitoring, and incident management .
Entry-Level Positions: Start as a cloud support engineer or junior DevOps position while building SRE skills . Some organizations hire Associate SRE Engineers with 0-2 years of experience .
FAQ Section
What is the typical salary range for Site Reliability Engineers?
Entry-level SREs can expect salaries from $75,000 to $110,000 (US), while senior roles reach $150,000 to $200,000. Staff and principal engineers can earn $200,000 or more . The demand for SRE professionals is projected to grow significantly .
How long does it take to become a competent SRE?
Self-paced learning can take 6-12 months to become a mildly skilled SRE, especially with a strong engineering background . Building expertise is an ongoing process requiring continuous learning and practical experience.
What certifications are valuable for SRE careers?
Valuable certifications include AWS Certified Solutions Architect, Certified Kubernetes Administrator (CKA), and SRE-specific certifications from APMG International . Certifications demonstrate commitment but practical experience often carries more weight in SRE hiring decisions .
Can I transition to SRE from a non-technical background?
Yes, with an intentional, hands-on approach. Choose a foundation (development or operations), practice incrementally, seek mentorship, and build practical experience . Real experience trumps theory, so start small and build up .
What’s the most important skill for an SRE?
While technical skills are essential, the most important attributes include staying calm under pressure, clear communication, and a mindset focused on systems thinking and continuous improvement . Automation, observability, and incident response skills are also critical .
Final Summary
Site Reliability Engineering offers IT professionals a rewarding career path that combines technical depth with strategic impact. SRE represents a fundamental shift from traditional operations approaches, applying software engineering principles to infrastructure challenges . The field has grown from its origins at Google to become an essential practice for organizations worldwide .
For IT professionals pursuing this path, the journey requires building strong foundations in Linux, networking, and programming before expanding into cloud platforms, containerization, and observability . The learning process typically takes 6-12 months of focused effort, but ongoing skill development is essential as the field evolves .